TCP
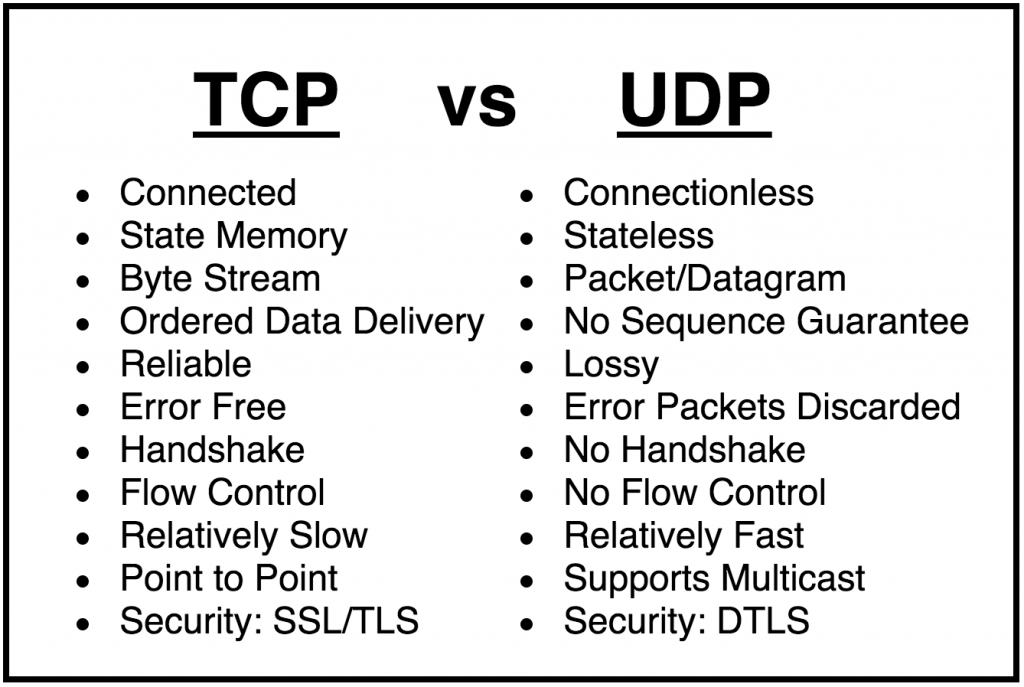
- TCP is an abbreviation of Transmission Control Protocol.
- This is a Transport Layer Protocol.
- TCP is a connection-oriented
protocol.
- It is a reliable protocol used for transport.
- This protocol seeks to deliver a stream of bytes from end-to-end in a particular order.
TCP is said to be connection-oriented because before one application process can begin to send data to another, the two processes must first “handshake” with each other—that is, they must establish a connection.
A TCP connection provides a full-duplex service: If there is a TCP connection between Process A on one host and Process B on another host, then application layer data can flow from Process A to Process B at the same time as application layer data flows from Process B to Process A.
A TCP connection is also always point-to-point, that is, between a single sender and a single receiver. So-called “multicasting”.
TCP segment structure

-
Source Port Address
It is a 16-bit field and is mainly defines the port number of the
application program in the host that is mainly used for sending the
segment. The purpose of the Source port address is the same as the
source port address in the header of the UDP.
-
Destination Port Address
This is also a 16-bit address and is mainly defines the port number of
the application program in the host that is mainly used for receiving
the segment. The purpose of the Destination port address is the same as the destination port address in the header of the UDP.
-
Sequence Number
It is a 32-bit field that mainly defines the number assigned to the first byte of data that is contained in the segment.
-
Acknowledgment Number
It is also a 32-bit field and is mainly used to define the byte number
that the receiver of the segment is expecting to receive from the other
party.
-
Header Length
It is a 4-bit field and is mainly used to indicate the number of 4-byte
words in the TCP header. The length of the header lies between 20 and
60 bytes.
-
Reserved
It is a 6-bit field and is mainly reserved for future use.
-
Control
This field mainly defines 6 different control bits or flags and among all only one can be set at that time.

These bits mainly enables the flow control, connection establishment, termination, and modes of transferring the data in TCP.
-
Window Size
This field is mainly used to define the size of the window. The size of
this field is 16-bit. It mainly contains the size of the data the
receiver can accept. The value of this field is mainly determined by the
receiver.
-
Checksum
It is a 16-bit field and is mainly contains the checksum. This field is mandatory in the case of TCP/IP.
-
Urgent Pointer
The size of this field is 16-bit and it is only valid in the case if
the urgent flag is set. This field is used only when the segment
contains urgent data.
-
Options
This field is represented in 32 bits.
Reliable Data Transfer
TCP creates a reliable data transfer service on top of IP’s unreliable best effort service. TCP’s reliable data transfer service ensures that the byte stream is exactly the same byte stream that was sent by the end system on the other side of the connection.
Flow Control
- The TCP provides the facility of Flow control.
- With the help of TCP,
the receiver of the data control the amount of the data that are to be
sent by the sender.
- The flow control is mainly done in order to prevent the receiver from being overwhelmed with the data.
- The numbering system also allows the TCP to use byte-oriented flow control.
Error Control
As TCP provides reliable services, thus it implements an error
control mechanism for this purpose. The Error control though considers
the segment as the unit of data for error detection. Error control is
byte-oriented in nature.
Congestion Control
Another main feature of TCP is that it facilitates Congestion Control
in the network. The Amount of the data that the sender sends is not
only controlled by the receiver, but congestion in the network also
determines it.
Connection Management/ Establishment
In TCP, the connection is established by using three-way handshaking.
The client application process first informs the client TCP that it wants to establish a connection to a process in the server. The TCP in the client then proceeds to establish a TCP connection with the TCP in the server in the following manner:
- The client-side TCP first sends a special TCP segment to the server-side TCP with its sequence number.
- The server, in return, sends its segment with its own sequence number as
well as the acknowledgement sequence, which is one more than the client
sequence number.
- When the client receives the acknowledgment of its
segment, then it sends the acknowledgment to the server.
In this way,
the connection is established between the client and the server.

Data Transfer Phase
After the establishment of the connection, the bidirectional data
transfer can take place. Both the client and server can send data and
acknowledgments.
Connection Termination Phase
The two parties that are involved in the data exchange can close the
connection, although it is initiated usually by the client. There ate
two ways for the connection termination:
TCP Congestion Control
The idea of TCP congestion control is for each source
to determine how much capacity is available in the network, so that it
knows how many packets it can safely have in transit. Once a given
source has this many packets in transit, it uses the arrival of an ACK
as a signal that one of its packets has left the network and that it is
therefore safe to insert a new packet into the network without adding to
the level of congestion. By using ACKs to pace the transmission of
packets, TCP is said to be self-clocking.
TCP uses a congestion window and a congestion policy that avoid
congestion.Previously, we assumed that only receiver can dictate the
sender’s window size. We ignored another entity here, the network. If
the network cannot deliver the data as fast as it is created by the
sender, it must tell the sender to slow down. In other words, in
addition to the receiver, the network is a second entity that determines
the size of the sender’s window.
TCP congestion-control algorithm
The algorithm has three major components:
(1) slow start- starts slowly increment is exponential to threshold
(2) congestion avoidance- After reaching the threshold increment is by 1
(3) fast recovery
TCP Congestion Control
TCP congestion control is often referred to as an additive-increase, multiplicative-decrease (AIMD) form of congestion control. AIMD congestion control gives rise to the “saw tooth” behavior.
Advantages of TCP
1.TCP performs data control and flow control mechanisms.
2.TCP provides excellent support for cross-platform.
3.The TCP protocol ensures the guaranteed delivery of the data.
4.It transmits the data from the sender to the receiver in a particular order.
5.It is a connection-oriented and reliable protocol.
6.It has a good relative throughput on the modem or on the LAN.
7.Provides error detection mechanism by using the checksum and error
correction mechanism is provided by using ARP or go-back protocol.
Disadvantages of TCP
1.It cannot be used for broadcast or multicast transmission.
2.There is an increase in the amount of overhead.
UDP
- The User Datagram Protocol, or UDP, is a communication protocol used
across the Internet for especially time-sensitive transmissions such as
video playback or DNS
lookups.
- The
UDP is a connectionless protocol as it does not create a virtual path
to transfer the data. It speeds up communications by not formally
establishing a
connection before data is transferred.
- It is a stateless protocol that means that the sender does not get the acknowledgement for the packet which has been sent.
- This allows data to be
transferred very quickly, but it can also cause packets to become lost in transit — and create opportunities for exploitation in the form of DDoS attacks.
Why do we require the UDP protocol?
As we know that the UDP is an unreliable protocol, but we still
require a UDP protocol in some cases. The UDP is deployed where the
packets require a large amount of bandwidth along with the actual data.
For example, in video streaming, acknowledging thousands of packets is
troublesome and wastes a lot of bandwidth. In the case of video
streaming, the loss of some packets couldn't create a problem, and it
can also be ignored.
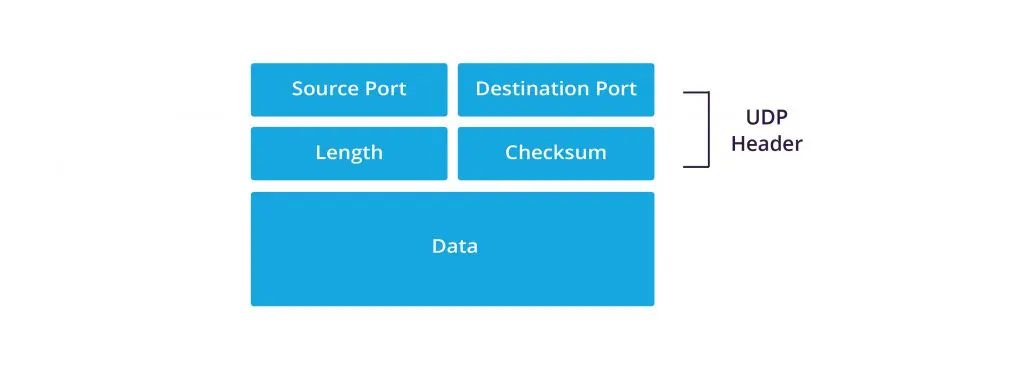
UDP segment structure
The UDP header contains four fields:
- Source port – The port of the device sending the
data. This field can be set to zero if the destination computer doesn’t
need to reply to the sender.
- Destination port – The port of the device receiving the data. UDP port numbers can be between 0 and 65,535.
- Length – Specifies the number of bytes comprising
the UDP header and the UDP payload data. The limit for the UDP length
field is determined by the underlying IP protocol used to transmit the
data.
- Checksum – The checksum
allows the receiving device to verify the integrity of the packet
header and payload. It is optional in IPv4 but was made mandatory in
IPv6.
Working
Like all networking protocols,
UDP is a standardized method for transferring data between two
computers in a network. Compared to other protocols, UDP accomplishes
this process in a simple fashion:
It sends packets (units of data
transmission) directly to a target computer, without establishing a
connection first, indicating the order of said packets, or checking
whether they arrived as intended. (UDP packets are referred to as
‘datagrams’.)
UDP is faster but less reliable than TCP,
another common transport protocol. In a TCP communication, the two
computers begin by establishing a connection via an automated process
called a ‘handshake.’ Only once this handshake has been completed will
one computer actually transfer data packets to the other.
UDP communications do not go through this process. Instead, one computer can simply begin sending data to the other:

In addition, TCP communications indicate the order in which data
packets should be received and confirm that packets arrive as intended.
If a packet does not arrive — e.g. due to congestion in intermediary
networks — TCP requires that it be re-sent. UDP communications do not
include any of this functionality.
These differences create some advantages.
Because UDP does not
require a ‘handshake’ or check whether data arrives properly, it is able
to transfer data much faster than TCP.
However, this speed creates tradeoffs. If a UDP datagram is lost in
transit, it will not be re-sent. As a result, applications that use UDP
must be able to tolerate errors, loss, and duplication.
The benefits and downsides of UDP
UDP has a number of benefits for different types of applications, including:
- No retransmission delays – UDP is suitable for
time-sensitive applications that can’t afford retransmission delays for
dropped packets. Examples include Voice over IP (VoIP), online games,
and media streaming.
- Speed – UDP’s speed makes it useful for query-response protocols such as DNS, in which data packets are small and transactional.
- Suitable for broadcasts – UDP’s lack of end-to-end
communication makes it suitable for broadcasts, in which transmitted
data packets are addressed as receivable by all devices on the internet.
UDP broadcasts can be received by large numbers of clients without
server-side overhead.
At the same time, UDP’s lack of connection requirements and data
verification can create a number of issues when transmitting packets.
These include:
- No guaranteed ordering of packets.
- No verification of the readiness of the computer receiving the message.
- No protection against duplicate packets.
- No guarantee the destination will receive all transmitted bytes.
UDP, however, does provide a checksum to verify individual packet
integrity.
UDP DDoS threats and vulnerabilities
UDP’s lack of a verification mechanism and end-to-end connections makes it vulnerable to a number of DDoS attacks. Attackers can spoof packets with arbitrary IP addresses, and reach the application directly with those packets.
This is in contrast to TCP, in which a sender must receive packets back from the receiver before communication can start.
UDP specific DDoS attacks include:
A UDP flood involves
large volumes of spoofed UDP packets being sent to multiple ports on a
single server, knowing that there is no way to verify the real source of
the packets. The server responds to all the requests with ICMP
‘Destination Unreachable’ messages, overwhelming its resources.
In addition to the traditional UDP flood, DDoS perpetrators often
stage generic network layer attacks by sending mass amounts of fake UDP
packets to create network congestion. These attacks can only be
mitigated by scaling up a network’s resources on demand, as is done when
using a cloud DDoS mitigation solution.
A DNS amplification attack
involves a perpetrator sending UDP packets with a spoofed IP address,
which corresponds to the IP of the victim, to its DNS resolvers. The DNS
resolvers then send their response to the victim. The attack is crafted
such that the DNS response is much larger than the original request,
which creates amplification of the original attack.
When done on a large scale with many clients and multiple DNS
resolvers, it can overwhelm the target system. A DDoS attack with
capacity of 27Gbps can be amplified to as much as 300Gbps using
amplification.
Attackers send UDP packets to ports on a server to determine which
ports are open. If a server responds with an ICMP ‘Destination
Unreachable’ message, the port is not open. If there is no such
response, the attacker infers that the port is open, and then use this information to plan an attack on the system.