2016
Module I
1 a. What role does logical view of documents play in information retrieval?
The effective retrieval of relevant information is directly affected both by the user task and by the logical view of the documents adopted by the retrieval system, as we now discuss.
Due to historical reasons,
documents in a collection are frequently represented through
a set of index terms or keywords. Such keywords might be extracted
directly from the text of the document or might be
specified by a human subject (as frequently
done in the information sciences arena). No matter whether these
representative keywords are derived automatically or generated by a
specialist, they provide a logical view of the
document.
Logical view of documents:
the representation of documents and Web pages adopted by the system.
The most common form is to represent the text of the document by a set
of indexing terms or keywords.
Modern computers are making it possible to represent a document by its full set of words. The retrieval system adopts a full text logical view (or representation) of the documents. With very large collections, however, even modern computers might have to reduce the set of representative keywords. This can be accomplished through the elimination of stopwords (such as articles and connectives), the use of stemming (which reduces distinct words to their common grammatical root), and the identification of noun groups (which eliminates adjectives, adverbs, and verbs). Further, compression might be employed. These operations are called text operations (or transformations). Text operations reduce the complexity of the document representation and allow moving the logical view from that of a full text to that of a set of index terms .
b.The vector space model of document retrieval uses the notion of an information space. How is term weighting used to position objects in the space? Why is term weighting important for effective document retrieval?
The Vector-Space Model (VSM) for Information Retrieval represents documents and queries as vectors of weights. Each weight is a measure of the importance of an index term in a document or a query, respectively.
Term weighting
- Term weighting is a procedure that takes place during the text indexing process in order to assess the value of each term to the document.
- Term weighting is the assignment of numerical values to terms that represent their importance in a document in order to improve retrieval effectiveness [8].
- Essentially it considers the relative importance of individual words in an information retrieval system, which can improve system effectiveness, since not all the terms in a given document collection are of equal importance.
- Weighing the terms is the means that enables the retrieval system to determine the importance of a given term in a certain document or a query.
- It is a crucial component of any information retrieval system, a component that has shown great potential for improving the retrieval effectiveness of an information retrieval system [7].
Term weights for information retrieval are estimated using term's co-occurrence as a measure of term dependency between them. The weight of vertex in the document graph is calculated based on both local and global information of that vertex.
c. A new IR algorithm yields the following answer to query ql (relevant docs are marked with a bullet):
01. d425
02. d87
03. d56 .
04. d32
05. dl24
06. d615 11. d193
07. d512 l2.d7l5
08. d129. 13. d8l0
09. d4 14. d5
10. d130 15. d3.
(i) Explain the evaluation metrics for the system'
(ii) Give the formula for mean average precision (MAP), and illustrate the metric by calculating System's MAP.
(iii) Draw a precision-recall.curve for the system. Explain how you arrived at your result.
2017
l.a An information retrieval evaluation measure is different from traditional evaluation.Why?
b Briefly explain the information retrieval process with a block diagram
Information retrieval (IR) may be defined as a software program that deals with the organization, storage, retrieval and evaluation of information from document repositories particularly textual information. The system assists users in finding the information they require but it does not explicitly return the answers of the questions. It informs the existence and location of documents that might consist of the required information. The documents that satisfy user’s requirement are called relevant documents. A perfect IR system will retrieve only relevant documents.
With the help of the following diagram, we can understand the process of information retrieval (IR) −
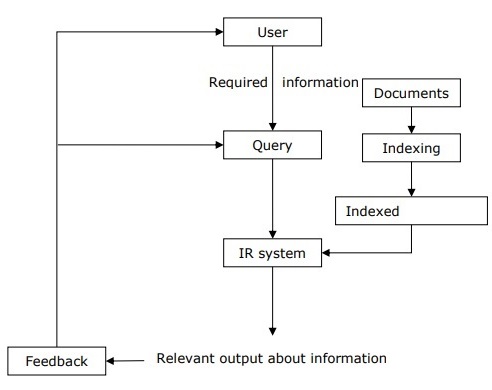
It is clear from the above diagram that a user who needs information will have to formulate a request in the form of query in natural language. Then the IR system will respond by retrieving the relevant output, in the form of documents, about the required information.
The main goal of IR research is to develop a model for retrieving information from the repositories of documents.
Information Retrieval (IR) Model
Mathematically, models are used in many scientific areas having objective to understand some phenomenon in the real world. A model of information retrieval predicts and explains what a user will find in relevance to the given query. IR model is basically a pattern that defines the above-mentioned aspects of retrieval procedure and consists of the following −
A model for documents.
A model for queries.
A matching function that compares queries to documents.
Mathematically, a retrieval model consists of −
D − Representation for documents.
R − Representation for queries.
F − The modeling framework for D, Q along with relationship between them.
R (q,di) − A similarity function which orders the documents with respect to the query. It is also called ranking.
Types of Information Retrieval (IR) Model
An information model (IR) model can be classified into the following three models −
Classical IR Model
It is the simplest and easy to implement IR model. This model is based on mathematical knowledge that was easily recognized and understood as well. Boolean, Vector and Probabilistic are the three classical IR models.
Non-Classical IR Model
It is completely opposite to classical IR model. Such kind of IR models are based on principles other than similarity, probability, Boolean operations. Information logic model, situation theory model and interaction models are the examples of non-classical IR model.
Alternative IR Model
It is the enhancement of classical IR model making use of some specific techniques from some other fields. Cluster model, fuzzy model and latent semantic indexing (LSI) models are the example of alternative IR model.
c. Consider a document collection with 5 relevant documents. Find the recall and precision at each document retrieval and plot the Precision/Recall curve(use interpolation). table given.
2018
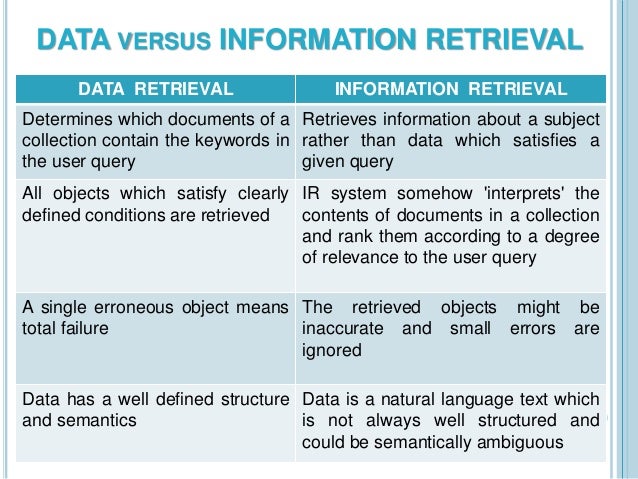
l.a Differentiate information retrieval from data retrieval
| Information Retrieval | Data Retrieval |
|---|---|
| The softwarethe program that deals with the organization, storage, retrieval, and evaluation of information from document repositories particularly textual information. | Data retrieval deals with obtaining data from a database management system such as ODBMS. It is A process of identifying and retrieving the data from the database, based on the query provided by user or application. |
| Retrieves information about a subject. | Determines the keywords in the user query and retrieves the data. |
| Small errors are likely to go unnoticed. | A single error object means total failure. |
| Not always well structured and is semantically ambiguous. | Has a well-defined structure and semantics. |
| Does not provide a solution to the user of the database system. | Provides solutions to the user of the database system. |
| The results obtained are approximate matches. | The results obtained are exact matches. |
| Results are ordered by relevance. | Results are unordered by relevance. |
| It is a probabilistic model. | It is a deterministic model. |
b Briefly explain the information retrieval process with a block diagram
c Consider a document collection with 4 relevant documents. Find the recall and precision at each document retrieval and plot the Precision/Recall curve (use interpolation). table given////repeated
2019
l.a Compare the process of data retrieval and information retrieval. ///repeated
b. Write note on Recall and Precision for retrieval performance evaluation. Explain with a simple example why Recall or Precision alone is not enough to quantify the performance of IR System. Explain any two alternative measures which combine recall and precision to get a better performance evaluation.
c. Describe the Retrieval process with simple, generic software architecture.
To describe the retrieval process, we use a simple and generic
software architecture as shown in
Figure ![[*]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_tAKtO45ht02ZqkKuXYHvRs2gJnlZuyoacpqdRReyH9jzZrOTrsfRaxcbNUqIjuDU1k8UeCyFJUvU-JkV3tfAkfm02PAoT-6ix4XYSiH5_KrncM_qk0J9gOLW1pshQ=s0-d)
Once the logical view of the documents is defined, the database
manager (using the DB Manager Module) builds an index of the text.
An index is a critical data structure because it allows fast searching over
large volumes of data. Different index structures might be used, but the most
popular one is the inverted file as indicated in
Figure

Given that the document database is indexed, the retrieval process can be initiated. The user first specifies a user need which is then parsed and transformed by the same text operations applied to the text. Then, query operations might be applied before the actual query, which provides a system representation for the user need, is generated. The query is then processed to obtain the retrieved documents. Fast query processing is made possible by the index structure previously built.
Before been sent to the user, the retrieved documents are ranked according to a likelihood of relevance. The user then examines the set of ranked documents in the search for useful information. At this point, he might pinpoint a subset of the documents seen as definitely of interest and initiate a user feedback cycle. In such a cycle, the system uses the documents selected by the user to change the query formulation. Hopefully, this modified query is a better representation of the real user need.
The small numbers outside thelower right corner of various boxes in
Figure
Consider now the user interfaces available with current information retrieval systems (including Web search engines and Web browsers). We first notice that the user almost never declares his information need. Instead, he is required to provide a direct representation for the query that the system will execute. Since most users have no knowledge of text and query operations, the query they provide is frequently inadequate. Therefore, it is not surprising to observe that poorly formulated queries lead to poor retrieval (as happens so often on the Web).
Module II
2a.Explain the effect of IDF and TF factors on inter cluster dissimilarity and intra cluster similarity.
b. Consider two documents Dl = (0.5, 0.8, 0.3) and D2 = (0'9' 0'4, 0'2) indexed by three terms' where the numbers represent term weights. Given the query q = (t.5, 1.0, 0) indexed by the same terms' find the cosine measures for the two documents'
c.Boolean model is more a data retrieval model than an information retrieval model' Justify your answer with.an example.
2017
2.a What is the difference between stemming and lemmatization
Stemming and Lemmatization are Text Normalization (or sometimes called Word Normalization) techniques in the field of Natural Language Processing that are used to prepare text, words, and documents for further processing.
Stemming just removes or stems the last few characters of a word, often leading to incorrect meanings and spelling. Lemmatization considers the context and converts the word to its meaningful base form, which is called Lemma. Sometimes, the same word can have multiple different Lemmas

b. Consider a very small collection that consists the following three documents with the
given contents:
d1 : "Kerala Technological University results"
d2: "Calicut Universitv results"
d3: "Karnataka University results"
Rank the documents for the query "Kerala results" using vector model. Assume tf-idf
ranking scheme and length normalization.
c. What is a positional index? Explain the algorithm for proximity intersection of 6
postings lists pl and p2
To enable faster phrase search performance and faster relevance ranking with the Phrase module, your project builds index data out of word positions.
This is called positional indexing. ... Positional indexing improves
the performance of multi-word phrase search, proximity search, and
certain relevance ranking modules.
Steps to build a Positional Index
- Fetch the document.
- Remove stop words, stem the resulting words.
- If the word is already present in the dictionary, add the document and the corresponding positions it appears in. Else, create a new entry.
- Also update the freqency of the word for each document, as well as the no. of documents it appears in.
2018
2.a TF-IDF is a good measure for weighting index terms in vector space model. Justify.
- In information retrieval, tf–idf, TF*IDF, or TFIDF, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.
- It is often used as a weighting factor in searches of information retrieval, text mining, and user modelling.
- The tf–idf value increases proportionally to the number of times a word appears in the document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently in general.
- tf–idf is one of the most popular term-weighting schemes today.
- A survey conducted in 2015 showed that 83% of text-based recommender systems in digital libraries use tf–idf.
Variations of the tf–idf weighting scheme are often used by search engines as a central tool in scoring and ranking a document's relevance given a user query. tf–idf can be successfully used for stop-words filtering in various subject fields, including text summarization and classification.
One of the simplest ranking functions is computed by summing the tf–idf for each query term; many more sophisticated ranking functions are variants of this simple model.
b. Consider a very small collection that consists the following three documents with the
given contents:
d1 : "Computer Science Engineering"
d2: "lnformation Science Engineering "
d3: "Computer science applications"
Rank the documents for the query "computer engineering" using vector model. Assume tf-idf ranking scheme and length normalization.
https://www.site.uottawa.ca/~diana/csi4107/cosine_tf_idf_example.pdf
c. What is a skip pointer? Explain the algorithm for the intersection of postings lists p1 and p2 using skip pointers.
Skip pointers are effectively shortcuts that allow us to avoid processing parts of the postings list that will not figure in the search results.
2019
2.a Explain how Euclidean distance function and cosine similarity can be used as
similarity measures. Will a document pair found 'similar' with cosine similarity
measure be similar with distance function similarity measure? Justify your
answer with a suitable example.
b. Write note on Boolean and Vector classical models for information retrieval. What are the advantages of vector model over Boolean model.
Boolean Retrieval
The (standard) Boolean model of information retrieval (BIR)[1] is a classical information retrieval (IR) model and, at the same time, the first and most-adopted one. It is used by many IR systems to this day.[citation needed] The BIR is based on Boolean logic and classical set theory in that both the documents to be searched and the user's query are conceived as sets of terms (a bag-of-words model). Retrieval is based on whether or not the documents contain the query terms.
Advantages:
• Users are under control of the search results
• The system is nearly transparent to the user
- Clean formalism
- Easy to implement
- Intuitive concept
- If the resulting document set is either too small or too big, it is directly clear which operators will produce respectively a bigger or smaller set.
- It gives (expert) users a sense of control over the system. It is immediately clear why a document has been retrieved given a query.
Disadvantages:
• Only give inclusion or exclusion of docs, not rankings
• Users would need to spend more effort in manually examining the returned
sets; sometimes it is very labor intensive
• No fuzziness allowed so the user must be very precise and good at writing
their queries
• However, in many cases users start a search because they don’t know the answer
(document)
- Exact matching may retrieve too few or too many documents
- Hard to translate a query into a Boolean expression
- All terms are equally weighted
- More like data retrieval than information retrieval
- Retrieval based on binary decision criteria with no notion of partial matching
- No ranking of the documents is provided (absence of a grading scale)
- Information need has to be translated into a Boolean expression, which most users find awkward
- The Boolean queries formulated by the users are most often too simplistic
- The model frequently returns either too few or too many documents in response to a user query
Vector space model or term vector model is an algebraic model for representing text documents (and any objects, in general) as vectors of identifiers (such as index terms).
Definitions[edit]
Documents and queries are represented as vectors.


Each dimension corresponds to a separate term. If a term occurs in the document, its value in the vector is non-zero. Several different ways of computing these values, also known as (term) weights, have been developed. One of the best known schemes is tf-idf weighting (see the example below).
The definition of term depends on the application. Typically terms are single words, keywords, or longer phrases. If words are chosen to be the terms, the dimensionality of the vector is the number of words in the vocabulary (the number of distinct words occurring in the corpus).
Vector operations can be used to compare documents with queries.
Applications[edit]

Relevance rankings of documents in a keyword search can be calculated, using the assumptions of document similarities theory, by comparing the deviation of angles between each document vector and the original query vector where the query is represented as a vector with same dimension as the vectors that represent the other documents.
In practice, it is easier to calculate the cosine of the angle between the vectors, instead of the angle itself:

Where is the intersection (i.e. the dot product) of the document (d2 in the figure to the right) and the query (q in the figure) vectors, is the norm of vector d2, and is the norm of vector q. The norm of a vector is calculated as such:




Using the cosine the similarity between document dj and query q can be calculated as:

As all vectors under consideration by this model are element wise nonnegative, a cosine value of zero means that the query and document vector are orthogonal and have no match (i.e. the query term does not exist in the document being considered). See cosine similarity for further information.
Advantages
- Simple model based on linear algebra
- Term weights not binary
- Allows computing a continuous degree of similarity between queries and documents
- Allows ranking documents according to their possible relevance
- Allows partial matching
- Long documents are poorly represented because they have poor similarity values (a small scalar product and a large dimensionality)
- Search keywords must precisely match document terms; word substrings might result in a "false positive match"
- Semantic sensitivity; documents with similar context but different term vocabulary won't be associated, resulting in a "false negative match".
- The order in which the terms appear in the document is lost in the vector space representation.
- Theoretically assumes terms are statistically independent.
- Weighting is intuitive but not very formal.
c. Explain the classic probabilistic model. What are the advantages and disadvantages of this model?
- Classic probabilistic model introduced in 1976 by Robersto and Sparck Jones
- Later became known as the binary independence retrieval (BIR) model.
- Attempts to capture the IR problem within a probabilistic framework.
- Probabilistic Model Computes the probability that the document is relevant to the query -ranks the documents according to their probability of being relevant to the query
- Assumption: there is a set R of relevant documents which maximizes the overall probability of relevance (R: ideal answer set)
- R is not known in advance initially assume a description (the terms) of R iteratively refine this description
- Given a user query, there is a set of documents that contains exactly the relevant documents.
• This set of documents is referred to as the ideal answer set.
• Thus, we can think of the querying process as a process of
specifying the properties of an ideal answer set.
• The problem is that we do not know exactly what these
properties are.