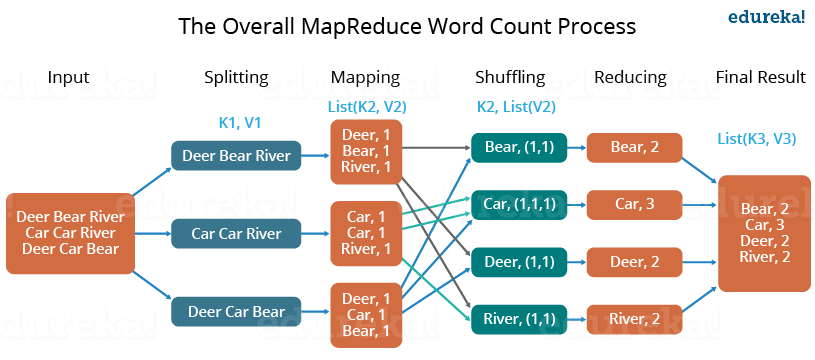
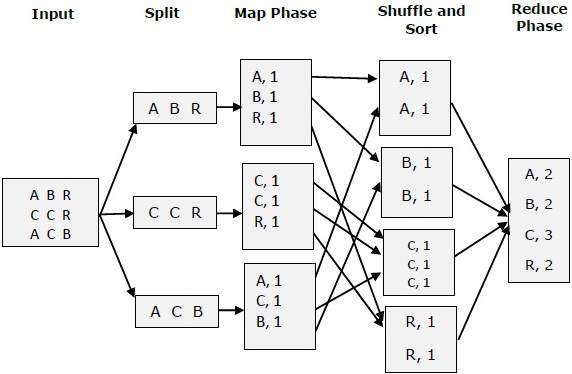
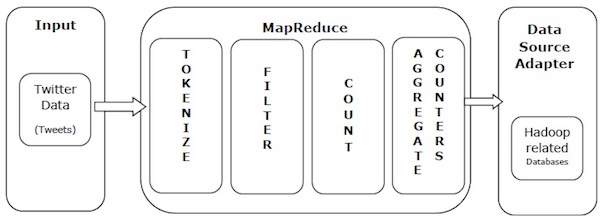
Every day, we create roughly 2.5 quintillion bytes of data
- 500 million tweets are sent
- 294 billion emails are sent
- 4 petabytes of data are created on Facebook
- 4 terabytes of data are created from each connected car
- 65 billion messages are sent on WhatsApp
- 5 billion searches are made
Big Data is a collection of data that is huge in
volume, yet growing exponentially with time.
It is a data with so large
size and complexity that none of traditional data management tools can
store it or process it efficiently. Big data is also a data but with
huge size.
Data: The quantities, characters, or symbols on which operations are performed
by a computer, which may be stored and transmitted in the form of
electrical signals and recorded on magnetic, optical, or mechanical
recording media.
Examples Of Big Data
* The New York Stock Exchange generates about one terabyte of new trade data per day.
* Social Media: The statistic shows that 500+terabytes of new data get ingested into the databases of social media site Facebook, every day. This data is mainly generated in terms of photo and video uploads, message exchanges, putting comments etc.
* A single Jet engine can generate 10+terabytes of data in 30 minutes of flight time. With many thousand flights per day, generation of data reaches up to many Petabytes.
Characteristics Of Big Data
Big data can be described by the following characteristics:
- Volume (Scale of data)
- Variety (Forms of data)
- Velocity (Analysis of data flow)
- Veracity (Uncertainty of data)
- Value
- Unfortunately, sometimes volatility isn’t within our control. The
volatility, sometimes referred to as another “V” of big data, is the
rate of change and lifetime of the data
Volume
- The name Big Data itself is
related to a size which is enormous.
- Size of data plays a very crucial
role in determining value out of data.
- Also, whether a particular data
can actually be considered as a Big Data or not, is dependent upon the
volume of data.
- Hence, 'Volume' is one characteristic which needs to be considered while dealing with Big Data.
As an example of a high-volume dataset, think about Facebook.
The world’s most popular social media platform now has more than 2.2
billion active users, many of whom spend hours each day posting updates,
commenting on images, liking posts, clicking on ads, playing games, and
doing a zillion other things that generate data that can be analyzed.
This is high-volume big data in no uncertain terms.
Variety
- Variety
refers to heterogeneous sources and the nature of data, both structured
and unstructured.
- During earlier days, spreadsheets and databases were
the only sources of data considered by most of the applications.
- Nowadays, data in the form of emails, photos, videos, monitoring
devices, PDFs, audio, etc. are also being considered in the analysis
applications.
- This variety of unstructured data poses certain issues for
storage, mining and analyzing data.
Facebook, of course, is just one source of big data. Imagine just how
much data can be sourced from a company’s website traffic, from review
sites, social media (not just Facebook, but Twitter, Pinterest,
Instagram, and all the rest of the gang as well), email, CRM systems,
mobile data, Google Ads – you name it. All these sources (and many more
besides) produce data that can be collected, stored, processed and
analyzed. When combined, they give us our second characteristic –
variety. Variety, indeed, is what makes it really, really big. Data scientists
and analysts aren’t just limited to collecting data from just one
source, but many. And this data can be broken down into three distinct
types – structured, semi-structured, and unstructured.
Velocity
- The term 'velocity' refers
to the speed of generation of data.
- How fast the data is generated and
processed to meet the demands, determines real potential in the data.
- Big
Data Velocity deals with the speed at which data flows in from sources
like business processes, application logs, networks, and social media
sites, sensors, Mobile devices, etc.
- The flow of data is massive and continuous.
Facebook messages, Twitter posts, credit card swipes and ecommerce sales transactions are all examples of high velocity data.
Veracity
This
refers to the inconsistency which can be shown by the data at times,
thus hampering the process of being able to handle and manage the data
effectively.
Veracity refers to the quality, accuracy and trustworthiness of data
that’s collected. As such, veracity is not necessarily a distinctive
characteristic of big data (as even little data needs to be
trustworthy), but due to the high volume, variety and velocity, high
reliability is of paramount importance if a business is draw accurate
conclusions from it. High veracity data is the truly valuable stuff that
contributes in a meaningful way to overall results. And it needs to be
high quality.
Value
Value sits right at the top of the pyramid and refers to an
organization’s ability to transform those tsunamis of data into real
business. With all the tools available today, pretty much any enterprise
can get started with big data
Types Of Big Data
Following are the types of Big Data:
- Structured
- Unstructured
- Semi-structured
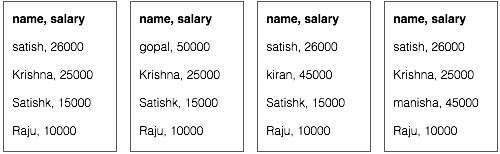
Structured
By structured data, we mean data that
can be processed, stored, and retrieved in a fixed format. It refers to
highly organized information that can be readily and seamlessly stored
and accessed from a database by simple search engine algorithms. For
instance, the employee table in a company database will be structured
as the employee details, their job positions, their salaries, etc., will be present in an organized manner.
Unstructured
Unstructured data refers to the data
that lacks any specific form or structure whatsoever. This makes it very
difficult and time-consuming to process and analyze unstructured data.
Email is an example of unstructured data. Structured and unstructured
are two important types of big data.
Semi-structured
Semi structured is the third type of
big data. Semi-structured data pertains to the data containing both the
formats mentioned above, that is, structured and unstructured data. To
be precise, it refers to the data that although has not been classified
under a particular repository (database), yet contains vital information
or tags that segregate individual elements within the data.
Importance
Ability to process Big Data brings in multiple benefits, such as-
Businesses can utilize outside intelligence while taking decisions- Access
to social data from search engines and sites like facebook, twitter are
enabling organizations to fine tune their business strategies.
Improved customer service- Traditional
customer feedback systems are getting replaced by new systems designed
with Big Data technologies. In these new systems, Big Data and natural
language processing technologies are being used to read and evaluate
consumer responses.
Early identification of risk to the product/services, if any
Better operational efficiency- Big
Data technologies can be used for creating a staging area or landing
zone for new data before identifying what data should be moved to the data warehouse.
In addition, such integration of Big Data technologies and data
warehouse helps an organization to offload infrequently accessed data.
Advantages of Big Data (Features)
- Opportunities to Make Better Decisions. ...
- Increasing Productivity and Efficiency. ...
- Reducing Costs. ...
- Improving Customer Service and Customer Experience. ...
- Fraud and Anomaly Detection. ...
- Greater Agility and Speed to Market. ...
- Questionable Data Quality. ...
- Heightened Security Risks.
- One of the
biggest advantages of Big Data is predictive analysis. Big Data
analytics tools can predict outcomes accurately, thereby, allowing
businesses and organizations to make better decisions, while
simultaneously optimizing their operational efficiencies and reducing
risks.
- By
harnessing data from social media platforms using Big Data analytics
tools, businesses around the world are streamlining their digital
marketing strategies to enhance the overall consumer experience. Big
Data provides insights into the customer pain points and allows
companies to improve upon their products and services.
- Being accurate, Big Data combines relevant data from multiple sources to produce highly actionable insights. Almost 43% of companies
lack the necessary tools to filter out irrelevant data, which
eventually costs them millions of dollars to hash out useful data from
the bulk. Big Data tools can help reduce this, saving you both time and
money.
- Big Data
analytics could help companies generate more sales leads which would
naturally mean a boost in revenue. Businesses are using Big Data
analytics tools to understand how well their products/services are doing
in the market and how the customers are responding to them. Thus, the
can understand better where to invest their time and money.
- With Big
Data insights, you can always stay a step ahead of your competitors. You
can screen the market to know what kind of promotions and offers your
rivals are providing, and then you can come up with better offers for
your customers. Also, Big Data insights allow you to learn customer
behavior to understand the customer trends and provide a highly
‘personalized’ experience to them.
Applications
1) Healthcare
- Big Data has already started to
create a huge difference in the healthcare sector.
- With the help of
predictive analytics, medical professionals and HCPs are now able to
provide personalized healthcare services to individual patients.
- Apart
from that, fitness wearables, telemedicine, remote monitoring – all
powered by Big Data and AI – are helping change lives for the better.
2) Academia
- Big Data is also helping enhance
education today.
- Education is no more limited to the physical bounds of
the classroom – there are numerous online educational courses to learn
from.
- Academic institutions are investing in digital courses powered by
Big Data technologies to aid the all-round development of budding
learners.
3) Banking
- The banking sector relies on Big Data
for fraud detection.
- Big Data tools can efficiently detect fraudulent
acts in real-time such as misuse of credit/debit cards, archival of
inspection tracks, faulty alteration in customer stats, etc.
4) Manufacturing
- According to TCS Global Trend Study, the most significant benefit of Big Data in manufacturing is improving the supply strategies and product quality.
- In the manufacturing sector, Big data helps create a transparent
infrastructure, thereby, predicting uncertainties and incompetencies
that can affect the business adversely.
5) IT
- One of the largest users of Big Data,
IT companies around the world are using Big Data to optimize their
functioning, enhance employee productivity, and minimize risks in
business operations.
- By combining Big Data technologies with ML and AI,
the IT sector is continually powering innovation to find solutions even
for the most complex of problems.
6) Retail
- Big Data has changed the way of
working in traditional brick and mortar retail stores.
- Over the years,
retailers have collected vast amounts of data from local demographic
surveys, POS scanners, RFID, customer loyalty cards, store inventory,
and so on.
- Now, they’ve started to leverage this data to create
personalized customer experiences, boost sales, increase revenue, and
deliver outstanding customer service.
-
Retailers are even using smart
sensors and Wi-Fi to track the movement of customers, the most
frequented aisles, for how long customers linger in the aisles, among
other things. They also gather social media data to understand what
customers are saying about their brand, their services, and tweak their
product design and marketing strategies accordingly.
7) Transportation
Big Data Analytics holds immense
value for the transportation industry. In countries across the world,
both private and government-run transportation companies use Big Data
technologies to optimize route planning, control traffic, manage road
congestion, and improve services. Additionally, transportation services
even use Big Data to revenue management, drive technological innovation,
enhance logistics, and of course, to gain the upper hand in the market.
Use cases: Fraud detection patterns
Traditionally, fraud discovery has been a tedious manual process. Common
methods of discovering and preventing fraud consist of investigative
work coupled with computer support. Computers can help in the alert
using very simple means, such as flagging all claims that exceed a
prespecified threshold. The obvious goal is to avoid large losses by
paying close attention to the larger claims.
Big Data can help you identify patterns in data that indicate fraud and you will know when and how to react.
Big Data analytics and Data Mining offers a range of techniques that can
go well beyond computer monitoring and identify suspicious cases based
on patterns that are suggestive of fraud. These patterns fall into three
categories.
- Unusual data. For
example, unusual medical treatment combinations, unusually high sales
prices with respect to comparatives, or unusual number of accident
claims for a person.
- Unexplained relationships between otherwise seemingly unrelated cases. For example, a real estate sales involving the same group of people, or different organizations with the same address.
- Generalizing characteristics of fraudulent cases. For
example, intense shopping or calling behavior of items/locations that
have not happened in the past, or a doctor’s billing for treatments and
procedures that he rarely billed for in the past. These patterns and
their discovery are detailed in the following sections. It should be
mentioned, that most of these approaches attempt to deal with
"non-revealing fraud". This is the common case. Only in cases of
"self-revealing" fraud (such as stolen credit cards) will it become
known at some time in the future that certain transactions had been
fraudulent. At that point only a reactive approach is possible, the
damage has already occurred; this may, however also set the basis for
attempting to generalize from these cases and help detect fraud when it
re-occurs in similar settings (see Generalizing characteristics of
fraud, below).
Unusual data
The
unusual data refer to three different situations: unusual combinations
of other quite acceptable entries, a value that is unusual with respect
to a comparison group, and an unusual value of and by itself. The latter
case is probably the easiest to deal with and is an example of "outlier
analysis". We are interested here only in outliers that are unusual,
but are still acceptable values; an entry of a negative number for the
number of staplers that a procurement clerk purchased would simply be a
data error, and presumably bear no relationship to fraud. An unusual
high value could be detected simply by employing descriptive statistics
tools, such as measures of mean and standard deviation, or a box plot;
for categorical values the same measures for the frequency of occurrence
would be a good indicator.
Somewhat
more difficult is the detection of values that are unusual only with
respect to a reference group. In a case of real estate sales price, the
price as such may not be very high, but it may be high for dwellings of
the same size and type in a given location and economic market. The
judgment that the value is unusual would only become apparent through
specific data analysis techniques..
Unexplained Relationships
The
unexplained relationships may refer to two or more seemingly unrelated
records having unexpectedly the same values for some of the fields. As
an example, in a money laundering scheme funds may be transferred
between two or more companies; it would be unexpected if some of the
companies in question have the same mailing address. Assuming that the
stored transactions consist of hundreds of variables and that there may
be a large number of transactions, the detection of such commonalities
is unlikely if left uninvestigated. When applying this technique to many
variables and/or variable combinations, the presence of an automated
tool is indispensable. Again positive findings do not necessarily
indicate fraud but are suggestive for further investigation.
Generalizing Characteristics of Fraud
Once
specific cases of fraud have been identified we can use them in order
to find features and commonalities that may help predict which other
transactions are likely to be fraudulent. These other transactions may
already have happened and been processed, or they may occur in the
future. In both cases, this type of analysis is called "predictive data
mining".
The potential advantage of
this method over all alternatives previously discussed is that its
reliability can be statistically assessed and verified. If the
reliability is high, then most of the investigative efforts can be
concentrated on handling the actual fraud cases, rather than screening
many cases, which may or may not be fraudulent.