Introduction: Overview of computer security
Computer Security: Security applied to an automated information system to attain the applicable objectives of preserving the integrity, availability, and confidentiality of information system resources, i.e protection of computer systems and information from harm, theft and unauthorized use.
Computer Security is mainly concerned with three main areas:
# Confidentiality
# Integrity
# Availability
CIA Triangle (Triad)
# It is simple but widely-applicable security model.
# The CIA Triad refers to the 3 goals of information security of the organization’s system, network and data.
# They are, “ Confidentiality, Integrity & Availability “.
Confidentiality
- Confidentiality
is roughly equivalent to privacy, that means that only the authorized
individuals/systems can view sensitive or classified information.
- The data being sent over the network should not be accessed by unauthorized individuals.
- The attacker may try to capture the data using different tools available and gain access to your information.
- Data encryption is a common method of ensuring confidentiality.
- Another
way to protect your data is through a VPN tunnel. VPN stands for
Virtual Private Network and helps the data to move securely over the
network.
Integrity
- Integrity is protecting information from being modified by unauthorized parties.
- The
ability to ensure that data is an accurate and unchanged representation
of the original secure information, Well, the idea here is making sure
that data has not been modified.
- Corruption of data is a failure
to maintain data integrity. Corruption can occur when information is
being compiled, stored, or transmitted.
- To check if our data
has been modified or not, we make use of a hash function such as SHA
(Secure Hash Algorithm) and MD5(Message Direct 5).
Availability
- Availability of information refers to, ensuring that authorized users are able to access the information when needed.
- This
means that the computing systems used to store and process the
information, the security controls used to protect it, and the
communication channels used to access it must be functioning correctly.
- Information can be erased or become inaccessible, resulting in “loss of availability.”
- Ensuring
availability also involves preventing denial-of-service attacks, such
as a flood of incoming messages to the target system, essentially
forcing it to shut down.
To make information available to those who need it and who can be trusted with it, organizations use authentication and authorization.
# Authentication is proving that a user is a person he or she claims to be.
# Authorization
is the act of determining whether a particular user (or computer
system) has the right to carry out a certain activity, such as reading a
file or running a program.
# Authentication and authorization go hand in hand.
# Users must be authenticated before carrying out the activity they are authorized to perform.
# Security is strong when the user cannot later deny that he or she performed the activity.
This is known as nonrepudiation.
# Accountability ( Tracing activities of an individual on a system) also supports non-repudiation
# These concepts of information security also apply to the term information security.
Challenges of Computer Security
- Computer
security is not as simple as it might first appear to the novice. But
the mechanisms used to meet the requirements such as confidentiality,
integrity, and availability can be quite complex, and understanding them
may involve rather a subtle reasoning (mental keenness).
- Potential attacks on developing a particular security mechanism or algorithm's security features.
- The
procedures used to provide particular services are often
counterintuitive (does not happen in the way you would expect it to)
- It
is necessary to decide where to use the various security mechanisms in
terms of physical placement (e.g., at what points in a network are
certain security mechanisms needed) & in a logical sense (e.g., at
what layer or layers of architecture such as TCP/IP should mechanisms be
placed)
- Security requires regular, even constant, monitoring, and this is difficult in today’s short-term, overloaded environment.
Components of Information System
Components of the information system are as follows:
# Hardware: Including computer systems and other data processing, data storage, and data communications devices.
# Software:
Including the operating system, system utilities, and applications.
These are used to control and coordinate the hardware components and for
analyzing and processing of the data.
# Data: Including files and databases, as well as security-related data, such as password files.
# Network: Refers
to the local and wide area network communication links, bridges,
routers, and so on. These resources facilitate the flow of information
in the organization.
# People: Every
system needs people if it is to be useful, probably the component that
most influences the success or failure of information systems. This
includes "not only the users, but those who operate and service the
computers, those who maintain the data, and those who support the
network of computers."
# Procedures: The policies that govern the operation of a computer system.
Need for Information Security
The purpose of information security is to ensure the key Objectives, i.e.
# Confidentiality
# Integrity
# Availability
Thus preventing & minimising the impact of security incidents.
The major needs for security in an organization are,
# Protecting the functionality of the organization
# Enabling the safe operation of applications
# Protecting the data that the organization collect and use
# Safeguarding technology assets in organizations
Protecting the functionality of the organization
- Implementing
information security in an organization can protect the technology and
information assets, by preventing, detecting, and responding to
threats.
- The decision-maker in organizations must set policy
and operates their organization in keeping with the complex, efficient,
and capable applications.
Enabling the safe operation of applications
- The
modern organization needs to create an environment that safeguards the
application, particularly those application that serves as important
elements of the infrastructure of the organization.
Protecting the data that the organization collect & use
- Data
in the organization can be in two forms that are either in rest or in
motion, the motion of data signifies that data is currently used or
processed by the system.
- The attacker may try to corrupt the data values which affects the integrity of the data.
Safeguarding technology assets in organisations
- The organization must add secure infrastructure services based on the size & scope of the organization.
- Additional security services may be needed as the organization expands.
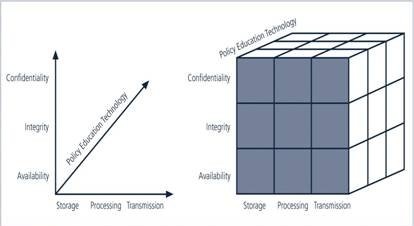
NSTISSC SECURITY MODEL
National Security Telecommunications & Information systems security committee’ document
# It is now called the National Training Standard for Information security professionals.
#
While the NSTISSC model covers the three dimensions of information
security, it omits a discussion of detailed guidelines and policies that
direct the implementation of controls.
#
The 3 dimensions of each axis become a 3x3x3 cube with 27 cells
representing areas that must be addressed to secure today’s Information
systems.
# To ensure system security, each of the 27 cells must be properly addressed during the security process.
#
For example, the intersection between technology, Integrity &
storage areas requires control or safeguard that addresses the need to
use technology to protect the Integrity of information while in storage.