- NoSQL database stands for "Not Only SQL" or "Not SQL."
- Non-relational Data Management System, that does not require a fixed schema.
- Major purpose- for distributed data stores with humongous(huge; enormous.) data storage needs.
- NoSQL is used for Big data and real-time web apps.
- For example, companies like Twitter, Facebook and Google collect terabytes of user data every single day.
Traditional RDBMS uses SQL syntax to store and retrieve data for further insights. Instead, a NoSQL database system encompasses a wide range of database technologies that can store structured, semi-structured, unstructured & polymorphic data. The system response time becomes slow when you use RDBMS for massive volumes of data.
To resolve this problem, we could "scale up" our systems by upgrading our existing hardware. This process is expensive.
The alternative for this issue is to distribute database load on multiple hosts whenever the load increases. This method is known as "scaling out."

NoSQL database is non-relational, so it scales out better than relational databases as they are designed with web applications in mind.
Features of NoSQL
-
They have higher scalability.
-
They use distributed computing.
-
They are cost effective.
-
They support flexible schema.
-
They can process both unstructured and semi-structured data.
-
There are no complex relationships, such as the ones between tables in an RDBMS.
Non-relational
- NoSQL databases never follow the relational model
- Never provide tables with flat fixed-column records
- Work with self-contained aggregates or BLOBs
- Doesn't require object-relational mapping and data normalization
- No complex features like query languages, query planners, referential integrity joins, ACID
Schema-free
- NoSQL databases are either schema-free or have relaxed schemas
- Do not require any sort of definition of the schema of the data
- Offers heterogeneous structures of data in the same domain

Simple API
- Offers easy to use interfaces for storage and querying data provided
- APIs allow low-level data manipulation & selection methods
- Text-based protocols mostly used with HTTP REST with JSON
- Mostly used no standard based NoSQL query language
- Web-enabled databases running as internet-facing services
Distributed
- Multiple NoSQL databases can be executed in a distributed fashion
- Offers auto-scaling and fail-over capabilities
- Often ACID concept can be sacrificed for scalability and throughput
- Mostly no synchronous replication between distributed nodes Asynchronous Multi-Master Replication, peer-to-peer, HDFS Replication
- Only providing eventual consistency
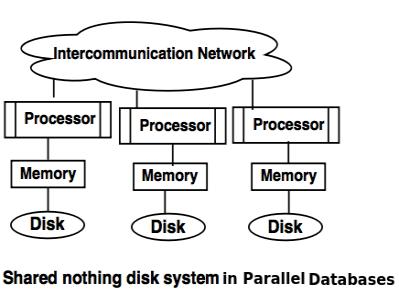
- Shared Nothing Architecture- This enables less coordination and higher distribution.

NoSQL is Shared Nothing.
Types of No SQL Databases
- Key-value Pair Based
- Column-oriented Graph
- Graphs based
- Document-oriented


Key Value Pair Based
Data is stored in key/value pairs. It is designed in such a way to handle lots of data and heavy load.
Key-value pair storage databases, store data as a hash table where each key is unique, and the value can be a JSON, BLOB(Binary Large Objects), string, etc.
For example, a key-value pair may contain a key like "Website" associated with a value like "Guru99".

It is one of the most basic NoSQL database example. This kind of NoSQL database is used as a collection, dictionaries, associative arrays, etc. Key value stores help the developer to store schema-less data. They work best for shopping cart contents.
Redis, Dynamo, Riak are some NoSQL examples of key-value store DataBases. They are all based on Amazon's Dynamo paper.
Advantages:
Can handle large amounts of data and heavy load,
Easy retrieval of data by keys.
Limitations:
Complex queries may attempt to involve multiple key-value pairs which may delay performance.
Data can be involving many-to-many relationships which may collide.
Column-based
Column-oriented databases work on columns and are based on BigTable paper by Google. Every column is treated separately. Values of single column databases are stored contiguously.

Column based NoSQL database
They deliver high performance on aggregation queries like SUM, COUNT, AVG, MIN etc. as the data is readily available in a column.
Column-based NoSQL databases are widely used to manage data warehouses, business intelligence, CRM, Library card catalogs,
HBase, Cassandra, HBase, Hypertable are NoSQL query examples of column based database.
Document-Oriented:
Document-Oriented NoSQL DB stores and retrieves data as a key value pair but the value part is stored as a document. The document is stored in JSON or XML formats. The value is understood by the DB and can be queried.

Relational Vs. Document
In this diagram on your left you can see we have rows and columns, and in the right, we have a document database which has a similar structure to JSON. Now for the relational database, you have to know what columns you have and so on. However, for a document database, you have data store like JSON object. You do not require to define which make it flexible.
The document type is mostly used for CMS systems, blogging platforms, real-time analytics & e-commerce applications. It should not use for complex transactions which require multiple operations or queries against varying aggregate structures.
Amazon SimpleDB, CouchDB, MongoDB, Riak, Lotus Notes, MongoDB, are popular Document originated DBMS systems.
Advantages:
This type of format is very useful and apt for semi-structured data.
Storage retrieval and managing of documents is easy.
Limitations:
Handling multiple documents is challenging
Aggregation operations may not work accurately.
Graph-Based
A graph type database stores entities as well the relations amongst those entities. The entity is stored as a node with the relationship as edges. An edge gives a relationship between nodes. Every node and edge has a unique identifier.

Compared to a relational database where tables are loosely connected, a Graph database is a multi-relational in nature. Traversing relationship is fast as they are already captured into the DB, and there is no need to calculate them.
Graph base database mostly used for social networks, logistics, spatial data.
Advantages:
Fastest traversal because of connections.
Spatial data can be easily handled.
Limitations:
Wrong connections may lead to infinite loops.
What is the CAP Theorem?
CAP theorem is also called brewer's theorem. It states that is impossible for a distributed data store to offer more than two out of three guarantees
- Consistency
- Availability
- Partition Tolerance
Consistency:
The data should remain consistent even after the execution of an operation. This means once data is written, any future read request should contain that data. For example, after updating the order status, all the clients should be able to see the same data.
Availability:
The database should always be available and responsive. It should not have any downtime.
Partition Tolerance:
Partition Tolerance means that the system should continue to function even if the communication among the servers is not stable. For example, the servers can be partitioned into multiple groups which may not communicate with each other. Here, if part of the database is unavailable, other parts are always unaffected.
BASE is an abbreviation for “basically available, soft-state, and eventual consistency,” and the meanings are described as follows.
(1) Basically available: The DB system can execute and always provide services. Some parts of the DB system may have partial failures and the rest of the DB system can continue to operate. Some NoSQL DBs typically keep several copies of specific data on different servers, which allows the DB system to respond to all queries even if few of the servers fail.
(2) Soft-state: The DB system does not require a state of strong consistency. Strong consistency means that no matter which replication of a certain data is updated, all later reading operations of the data must be able to obtain the latest information.
(3) Eventual consistency: The DB system needs to meet the consistency requirement after a
certain time. Sometimes the DB may be in an inconsistent state. For example, some NoSQL
DBs keep multiple copies of certain data on multiple servers. However, these copies may be
inconsistent in a short time, which may happen when a copy of the data is updated while the
other copies continue to have data from the old version. Eventually, the replication
mechanism in the NoSQL DB system will update all replicas to be consistent.
Advantages of NoSQL
- Can be used as Primary or Analytic Data Source
- Big Data Capability
- No Single Point of Failure
- Easy Replication
- No Need for Separate Caching Layer
- It provides fast performance and horizontal scalability.
- Can handle structured, semi-structured, and unstructured data with equal effect
- Object-oriented programming which is easy to use and flexible
- NoSQL databases don't need a dedicated high-performance server
- Support Key Developer Languages and Platforms
- Simple to implement than using RDBMS
- It can serve as the primary data source for online applications.
- Handles big data which manages data velocity, variety, volume, and complexity
- Excels at distributed database and multi-data center operations
- Eliminates the need for a specific caching layer to store data
- Offers a flexible schema design which can easily be altered without downtime or service disruption
Disadvantages of NoSQL
- No standardization rules
- Limited query capabilities
- RDBMS databases and tools are comparatively mature
- It does not offer any traditional database capabilities, like consistency when multiple transactions are performed simultaneously.
- When the volume of data increases it is difficult to maintain unique values as keys become difficult
- Doesn't work as well with relational data
- The learning curve is stiff for new developers
- Open source options so not so popular for enterprises.
When should NoSQL be used:
1. When huge amount of data need to be stored and retrieved .
2. The relationship between the data you store is not that important
3. The data changing over time and is not structured.
4. Support of Constraints and Joins is not required at database level
5. The data is growing continuously and you need to scale the database regular to handle the data.