Module2
2015
1. What is range partitioning?
- Range partitioning is a type of relational database partitioning where the partition is based on a predefined range for a specific data field such as uniquely numbered IDs, dates or simple values like currency.
- A partitioning key column is assigned with a specific range, and when a data entry fits this range, it is assigned to this partition; otherwise it is placed in another partition where it fits.
- In a range partitioned table, rows are distributed based on a "partitioning key" where the only requisite is whether or not the data falls within the range specification of the key.
- For example, if the partition key is a date column, and January 2015 is a partition, then all data containing values from January 1, 2015 to January 31, 2015 will be placed in this partition.
- Range partitioning is quite useful for applications requiring high performance
- This makes data segregation easy and access to each smaller partition is fast
Characteristics of range partitioning:
- Each partition has an exclusive upper bound.
- Each partition has a non-inclusive lower bound, except for the very first partition.
2. Discuss about inter and intra query parallelism in parallel database
Parallelism is used to support speedup, where queries are executed faster because more resources, such as processors and disks, are provided. Parallelism is also used to provide scale-up, where increasing workloads are managed without increase response-time, via an increase in the degree of parallelism.
Intraquery Parallelism
- Intraquery parallelism defines the execution of a single query in parallel on multiple processors and disks.
- Using intraquery parallelism is essential for speeding up long-running queries.
- This application of parallelism decomposes the serial SQL, query into lower-level operations such as scan, join, sort, and aggregation.
- These lower-level operations are executed concurrently, in parallel.
It is the form of parallelism where Single Query is executed in parallel on many processors.
Types
Intra-operation parallelism – the process of speeding up a query through parallelizing the execution of individual operations. The operations which can be parallelized are Sort, Join, Projection, Selection and so on.
Inter-operation parallelism – the process of speeding up a query through parallelizing various operations which are part of the query. For example, a query which involves join of 4 tables can be executed in parallel in two processors in such a way that each processor shall join two relations locally and the result1 and result2 can be joined further to produce the final result.
Example Database systems which support Intra-query Parallelism
Informix, Terradata.
Advantages
To speed up a single complex long running queries.
Best suited for complex scientific calculations (queries).
Supported Parallel Database Architectures
Interquery Parallelism
- In interquery parallelism, different queries or transaction execute in parallel with one another.
- This form of parallelism can increase transactions throughput.
- The primary use of interquery parallelism is to scale up a transaction processing system to support a more significant number of transactions per second.
It is a form of parallelism where many different Queries or Transactions are executed in parallel with one another on many processors.
Advantages
It increases Transaction Throughput. That is, number of transactions executed in a given time can be increased.
It scales up the Transaction processing system. Hence, best suited for On-Line Transaction Processing (OLTP) systems.
Supported Parallel Database Architectures
It is easy to implement in Shared Memory Parallel System. Lock tables and Log information are maintained in the same memory. Hence, it is easy to handle those transactions which shares locks with other transactions. Locking and logging can be done efficiently.
In other parallel architectures like Shared Disk and Shared Nothing, the locking and logging must be done through message passing between processors, which is considered as costly operation when compared Shared Memory Parallel architecture. Cache coherency problem would occur.
Example Database systems which support Inter-query Parallelism
Oracle 8 and Oracle Rdb
3. Briefly describe the different types of architectures in DBMS
2016
1. Differentiate between parallel systems and Distributed System.
2. Discuss how intra and inter query parallelism is obtained in parallel database.
3.. Discuss various types of database system architecture with diagram.
2017
1. Explain Range partitioning sorting briefly
Works in 2 steps.
- Range partitioning the relation
- Sorting each partition separately
Steps:
Point to note:
2. With pipelined parallelism, it is often a good idea to perform several operations in a
pipeline on a single processor ,even when many processors are available.Justify.
a. Explain why.
b. Would the arguments you advanced in part a hold if the machine
has a shared-memory architecture? Explain why or why not.
c. Would the arguments in part a hold with independent parallelism? (That is, are there
cases where, even if the operations are not pipelined and there are many processors
available, it is still a good idea to perform several operations on the same processor?)
a. The speed-up obtained by parallelizing the operations would be offset by the data transfer overhead, as each tuple produced by an operator would have to be transferred to its consumer, which is running on a different processor.
b. In a shared-memory architecture, transferring the tuples is very efficient. So the above argument does not hold to any significant degree.
c. Even if two operations are independent, it may be that they both supply their outputs to a common third operator. In that case, running all three on the same processor may be better than transferring tuples across processors.
a. Increasing the throughput of a system with many small queries
b. Increasing the throughput of a system with a few large queries, when the number of disks and processors is large
Answer:
a. When there are many small queries, inter-query parallelism gives good throughput. Parallelizing each of these small queries would increase the initiation overhead, without any significant reduction
in response time.
b. With a few large queries, intra-query parallelism is essential to get fast response times. Given that there are large number of processors and disks, only intra-operation parallelism can take
advantage of the parallel hardware – for queries typically have
2018
1. Differentiate inter and intra operation parallelism
Intra-operation parallelism – the process of speeding up a query through parallelizing the execution of individual operations. The operations which can be parallelized are Sort, Join, Projection, Selection and so on.
Inter-operation parallelism – the process of speeding up a query through parallelizing various operations which are part of the query. For example, a query which involves join of 4 tables can be executed in parallel in two processors in such a way that each processor shall join two relations locally and the result1 and result2 can be joined further to produce the final result.
Example Database systems which support Intra-query Parallelism
Explain about parallel database
Parallel Databases :
Nowadays organizations need to handle a huge amount of data with a high transfer rate. For such requirements, the client-server or centralized system is not efficient. With the need to improve the efficiency of the system, the concept of the parallel database comes in picture. A parallel database system seeks to improve the performance of the system through parallelizing concepts.
Need :
Multiple resources like CPUs and Disks are used in parallel. The operations are performed simultaneously, as opposed to serial processing. A parallel server can allow access to a single database by users on multiple machines. It also performs many parallelization operations like data loading, query processing, building indexes, and evaluating queries.
Advantages
Performance Improvement –By connecting multiple resources like CPU and disks in parallel we can significantly increase the performance of the system.
High availability – In the parallel database, nodes have less contact with each other, so the failure of one node doesn’t cause for failure of the entire system. This amounts to significantly higher database availability.
Proper resource utilization – Due to parallel execution, the CPU will never be ideal. Thus, proper utilization of resources is there.
4. Increase Reliability – When one site fails, the execution can continue with another available site which is having a copy of data. Making the system more reliable.
Performance Measurement of Databases :
Here, we will emphasize the performance measurement factor-like Speedup and Scale-up.
A fixed-sized problem executing on a small system is given to an N-times larger system. i.e Speedup is the execution of a task in less time by the increasing the degree of parallelism.

Scaleup
It is the process of handling a large task in the same amount of time by increasing the degree of parallelism. It increases the size of both the problem and the system N-times larger system used to perform N-times larger job.
Scale-up is linear if equation equals 1.

3. Discuss in detail about various Database system Architecture Design
2019
1. Differentiate data servers and transaction servers
2. With the help of an algorithm and example, explain how fragment and replicate join is performed during intra query parallelism

Points to Note
3. Explain various parallel database architecture.How the execution of data varies according to the use of different architectures.
Shared memory system
- Shared memory system uses multiple processors which is attached to a global shared memory via intercommunication channel or communication bus.
- Shared memory system have large amount of cache memory at each processors, so referencing of the shared memory is avoided.
- If a processor performs a write operation to memory location, the data should be updated or removed from that location.
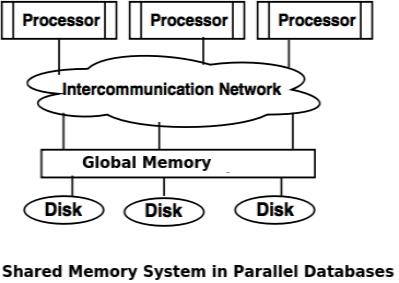
Advantages of Shared memory system
- Data is easily accessible to any processor.
- One processor can send message to other efficiently.
- Waiting time of processors is increased due to more number of processors.
- Bandwidth problem.
Shared Disk System
- Shared disk system uses multiple processors which are accessible to multiple disks via intercommunication channel and every processor has local memory.
- Each processor has its own memory so the data sharing is efficient.
- The system built around this system are called as clusters.
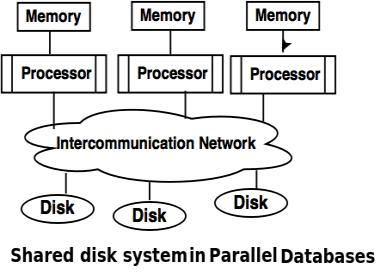
Advantages of Shared Disk System
- Fault tolerance is achieved using shared disk system.
Fault tolerance: If a processor or its memory fails, the other processor can complete the task. This is called as fault tolerance.
- Shared disk system has limited scalability as large amount of data travels through the interconnection channel.
- If more processors are added the existing processors are slowed down.
Digital Equipment Corporation(DEC): DEC cluster running relational databases use the shared disk system and now owned by Oracle.
Shared nothing disk system
- Each processor in the shared nothing system has its own local memory and local disk.
- Processors can communicate with each other through intercommunication channel.
- Any processor can act as a server to serve the data which is stored on local disk.
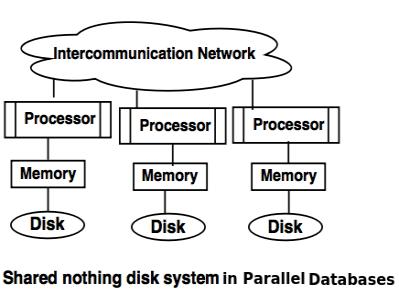
Advantages of Shared nothing disk system
- Number of processors and disk can be connected as per the requirement in share nothing disk system.
- Shared nothing disk system can support for many processor, which makes the system more scalable.
- Data partitioning is required in shared nothing disk system.
- Cost of communication for accessing local disk is much higher.
- Tera data database machine.
- The Grace and Gamma research prototypes.
Hierarchical System or Non-Uniform Memory Architecture
- Hierarchical model system is a hybrid of shared memory system, shared disk system and shared nothing system.
- Hierarchical model is also known as Non-Uniform Memory Architecture (NUMA).
- In this system each group of processor has a local memory. But processors from other groups can access memory which is associated with the other group in coherent.
- NUMA uses local and remote memory(Memory from other group), hence it will take longer time to communicate with each other.
- Improves the scalability of the system.
- Memory bottleneck(shortage of memory) problem is minimized in this architecture.
The cost of the architecture is higher compared to other architectures.