In a huge database structure, it is very inefficient to search all the index values and reach the desired data. Hashing technique is used to calculate the direct location of a data record on the disk without using index structure.
In this technique, data is stored at the data blocks whose address is generated by using the hashing function. The memory location where these records are stored is known as data bucket or data blocks.
Hashing-
Hash Table- A hash table is a data structure for storing a set of items, so that we can quickly determine whether an
item is or is not in the set.
Hash Function- maps every possible item x to a small integer h(x). Then we store x in slot h(x) in an array. The array is the hash table.
Let’s be a little more specific. We want to store a set of n items. Each item is an element of some finite 1 set U called the universe; we use u to denote the size of the universe, which is just the number of items in U . A hash table is an array T [1 .. m], where m is another positive integer, which we call the table size. Typically, m is much smaller than u. A hash function is any function of the form h: U → {0, 1, . . . , m − 1}, mapping each possible item in U to a slot in the hash table. We say that an item x hashes to the slot T [h(x)].
Limitations of Static hashing
When the table is to be full, overflows increase. As overflows increase, the overall performance decreases. –We cannot just copy entries from smaller into a corresponding buckets of a bigger table. Allow the size of dictionary to grow and shrink. –The size of hash table can be changed dynamically.
Dynamic Hashing
- The dynamic hashing method is used to overcome the problems of static hashing like bucket overflow.
- In this method, data buckets grow or shrink as the records increases or decreases. This method is also known as Extendable hashing method.
- This method makes hashing dynamic, i.e., it allows insertion or deletion without resulting in poor performance.
How to search a key
- First, calculate the hash address of the key.
- Check how many bits are used in the directory, and these bits are called as i.
- Take the least significant i bits of the hash address. This gives an index of the directory.
- Now using the index, go to the directory and find bucket address where the record might be.
How to insert a new record
- Firstly, you have to follow the same procedure for retrieval, ending up in some bucket.
- If there is still space in that bucket, then place the record in it.
- If the bucket is full, then we will split the bucket and redistribute the records.
-
Easy to compute: It should be easy to compute and must not become an algorithm in itself.
-
Uniform distribution: It should provide a uniform distribution across the hash table and should not result in clustering.
-
Less collisions: Collisions occur when pairs of elements are mapped to the same hash value. These should be avoided.
Note: Irrespective of how good a hash function is, collisions are bound to occur. Therefore, to maintain the performance of a hash table, it is important to manage collisions through various collision resolution techniques.
For example:
Consider the following grouping of keys into buckets, depending on the prefix of their hash address:
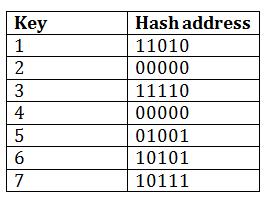
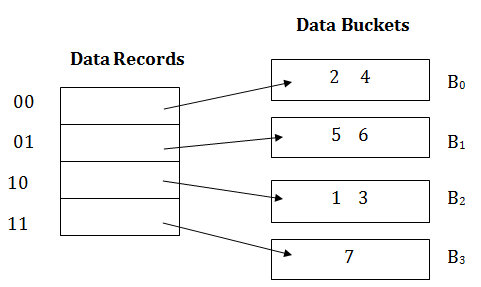
The last two bits of 2 and 4 are 00. So it will go into bucket B0. The last two bits of 5 and 6 are 01, so it will go into bucket B1. The last two bits of 1 and 3 are 10, so it will go into bucket B2. The last two bits of 7 are 11, so it will go into B3.
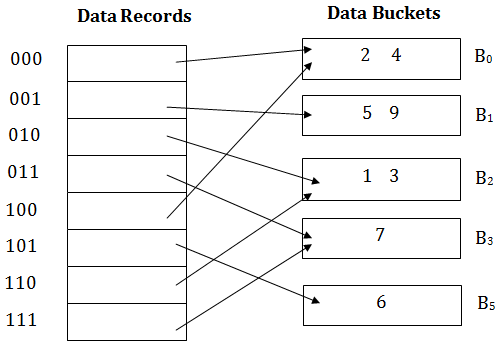
Insert key 9 with hash address 10001 into the above structure:
- Since key 9 has hash address 10001, it must go into the first bucket. But bucket B1 is full, so it will get split.
- The splitting will separate 5, 9 from 6 since last three bits of 5, 9 are 001, so it will go into bucket B1, and the last three bits of 6 are 101, so it will go into bucket B5.
- Keys 2 and 4 are still in B0. The record in B0 pointed by the 000 and 100 entry because last two bits of both the entry are 00.
- Keys 1 and 3 are still in B2. The record in B2 pointed by the 010 and 110 entry because last two bits of both the entry are 10.
- Key 7 are still in B3. The record in B3 pointed by the 111 and 011 entry because last two bits of both the entry are 11.
Advantages of dynamic hashing
- In this method, the performance does not decrease as the data grows in the system. It simply increases the size of memory to accommodate the data.
- In this method, memory is well utilized as it grows and shrinks with the data. There will not be any unused memory lying.
- This method is good for the dynamic database where data grows and shrinks frequently.
Disadvantages of dynamic hashing
- In this method, if the data size increases then the bucket size is also increased. These addresses of data will be maintained in the bucket address table. This is because the data address will keep changing as buckets grow and shrink. If there is a huge increase in data, maintaining the bucket address table becomes tedious.
- In this case, the bucket overflow situation will also occur. But it might take little time to reach this situation than static hashing.
UNIVERSAL HASHING
- Universal hashing (in a randomized algorithm or data structure) refers to selecting a hash function at random from a family of hash functions with a certain mathematical property.
- This guarantees a low number of collisions in expectation, even if the data is chosen by an adversary.
- Many universal families are known (for hashing integers, vectors, strings), and their evaluation is often very efficient.
- Universal hashing has numerous uses in computer
science, for example in implementations of hash tables, randomized algorithms, and cryptography.
