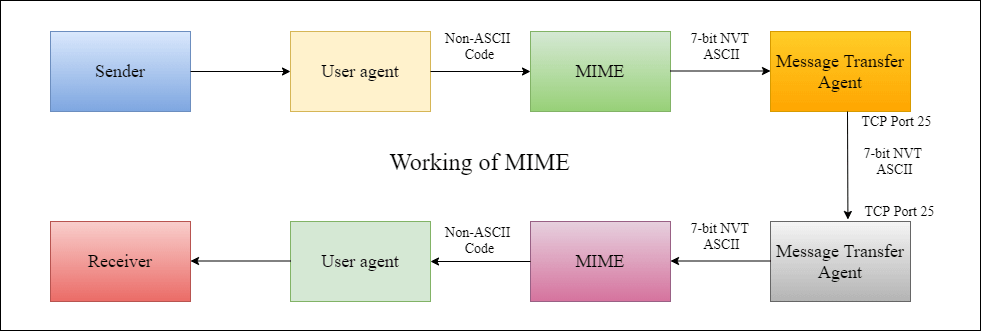
The Domain Name System (DNS) is the phonebook of the Internet. Humans access information online through domain names, like nytimes.com or espn.com. Web browsers interact through Internet Protocol (IP) addresses. DNS translates domain names to IP addresses so browsers can load Internet resources.
- DNS is short for Domain Name Service or Domain Name System.
- It is an application layer protocol.
- DNS is a host name to IP Address translation service.
- It converts the names we type in our web browser address bar to the IP Address of web servers hosting those sites.
WHY DNS?
- IP Addresses are not static and may change dynamically.So, a mapping is required which maps the domain names to the IP Addresses of their web servers.
- IP Addresses are a complex series of numbers. So, it is difficult to remember IP Addresses directly while it is easy to remember names.
The DNS is (1) a distributed database implemented in a hierarchy of DNS servers, and (2) an application-layer protocol that allows hosts to query the distributed database.
DNS provides a few other important services in addition to translating host- names to IP addresses:
• Host aliasing. A host with a complicated hostname can have one or more alias names.
• Mail server aliasing. For obvious reasons, it is highly desirable that e-mail addresses be mnemonic.
• Load distribution. DNS is also used to perform load distribution among replicated servers, such as replicated Web servers.
Working
A simple design for DNS would have one DNS server that contains all the mappings. In this centralized design, clients simply direct all queries to the single DNS server, and the DNS server responds directly to the querying clients. Although the simplicity of this design is attractive, it is inappropriate for today’s Internet, with its vast (and growing) number of hosts. The problems with a centralized design include:
• A single point of failure. If the DNS server crashes, so does the entire Internet.
• Traffic volume. A single DNS server would have to handle all DNS queries (for all the HTTP requests and e-mail messages generated from hundreds of millions of hosts).
• Distant centralized database. A single DNS server cannot be “close to” all the querying clients. If we put the single DNS server in New York City, then all queries from Australia must travel to the other side of the globe, perhaps over slow and congested links. This can lead to significant delays.
• Maintenance. The single DNS server would have to keep records for all Internet hosts. Not only would this centralized database be huge, but it would have to be updated frequently to account for every new host.
A Distributed, Hierarchical Database
In order to deal with the issue of scale, the DNS uses a large number of servers, organized in a hierarchical fashion and distributed around the world. No single DNS server has all of the mappings for all of the hosts in the Internet. Instead, the mappings are distributed across the DNS servers. To a first approximation, there are three classes of DNS servers—
root DNS servers-In the Internet there are 13 root DNS servers (labeled A through M), most of which are located in North America.
top-level domain (TLD) DNS servers- These servers are responsible for top-level domains such as com, org, net, edu, and gov, and all of the country top-level domains such as uk, fr, ca, and jp.
authoritative DNS servers-Every organization with publicly accessible hosts (such as Web servers and mail servers) on the Internet must provide publicly accessible DNS records that map the names of those hosts to IP addresses.
DNS Resolution is a process of resolving a domain name onto an IP Address.
DNS Lookup
- A user types ‘example.com’ into a web browser and the query travels into the Internet and is received by a DNS recursive resolver.
- The resolver then queries a DNS root nameserver (.).
- The root server then responds to the resolver with the address of a Top Level Domain (TLD) DNS server (such as .com or .net), which stores the information for its domains. When searching for example.com, our request is pointed toward the .com TLD.
- The resolver then makes a request to the .com TLD.
- The TLD server then responds with the IP address of the domain’s nameserver, example.com.
- Lastly, the recursive resolver sends a query to the domain’s nameserver.
- The IP address for example.com is then returned to the resolver from the nameserver.
- The DNS resolver then responds to the web browser with the IP address of the domain requested initially.
- The browser makes a HTTP request to the IP address.
- The server at that IP returns the webpage to be rendered in the browser (step 10).
Once the 8 steps of the DNS lookup have returned the IP address for example.com, the browser is able to make the request for the web page:
DNS queries:
- Recursive query - In a recursive query, a DNS client requires that a DNS server (typically a DNS recursive resolver) will respond to the client with either the requested resource record or an error message if the resolver can't find the record.
- Iterative query - in this situation the DNS client will allow a DNS server to return the best answer it can. If the queried DNS server does not have a match for the query name, it will return a referral to a DNS server authoritative for a lower level of the domain namespace. The DNS client will then make a query to the referral address. This process continues with additional DNS servers down the query chain until either an error or timeout occurs.
DNS caching
- The purpose of caching is to temporarily stored data in a location that results in improvements in performance and reliability for data requests.
- DNS caching involves storing data closer to the requesting client so that the DNS query can be resolved earlier and additional queries further down the DNS lookup chain can be avoided, thereby improving load times and reducing bandwidth/CPU consumption.
- DNS data can be cached in a variety of locations, each of which will store DNS records for a set amount of time determined by a time-to-live (TTL).
OpenDNS
Suppose DNS server of your ISP is slow, the time it takes to resolve the web address adds up to the overall loading time of the website.
To solve this problem, we
look at a simple and reliable service called OpenDNS that speeds up
your Internet connection and also handles some other very important
issues.
OpenDNS is an American company providing Domain Name System (DNS) resolution services—with features such as phishing protection, optional content filtering, and DNS lookup in its DNS servers.
Setup
- There are no software to install, it’s very easy to set up and the price is just right - $0.
- To use OpenDNS, all you have to do is open your Network Connections or Router’s settings page and update the default DNS server to point to the OpenDNS nameservers that are 208.67.222.222 and 208.67.220.220.
- The whole process takes a few seconds but with this single step alone, you just made your computer safer and increased the overall browsing speed.
- Unlike the DNS servers of your less reliable ISP, OpenDNS servers store the IP addresses of millions of websites in their cache so it would take less time to resolve your requests. So if you have asked for an IP address of a website that has been previously requested by another OpenDNS user, you will get the reply instantly.
- Another huge advantage of using OpenDNS is that it blocks phishing websites from loading on your computer. It uses data from Phishtank, a community site that is also used by Yahoo! Mail to determine if some particular website is part of any online phishing scam.
- OpenDNS also takes care of any typos that you commit while typing the name of popular websites. For instance, if you type www.gogle.com omitting the additional “o” by mistake, OpenDNS will open the main www.google.com site automatically.
- If you are a parent worried about kids visiting adult websites on the home computer, you can configure OpenDNS to block any adult website from loading on the computer. In fact, quite a few business places use OpenDNS to block social sites like MySpace and Facebook on employee computers.
- Power users can assign abbreviations or OpenDNS Shortcuts to access their favourite websites more quickly.