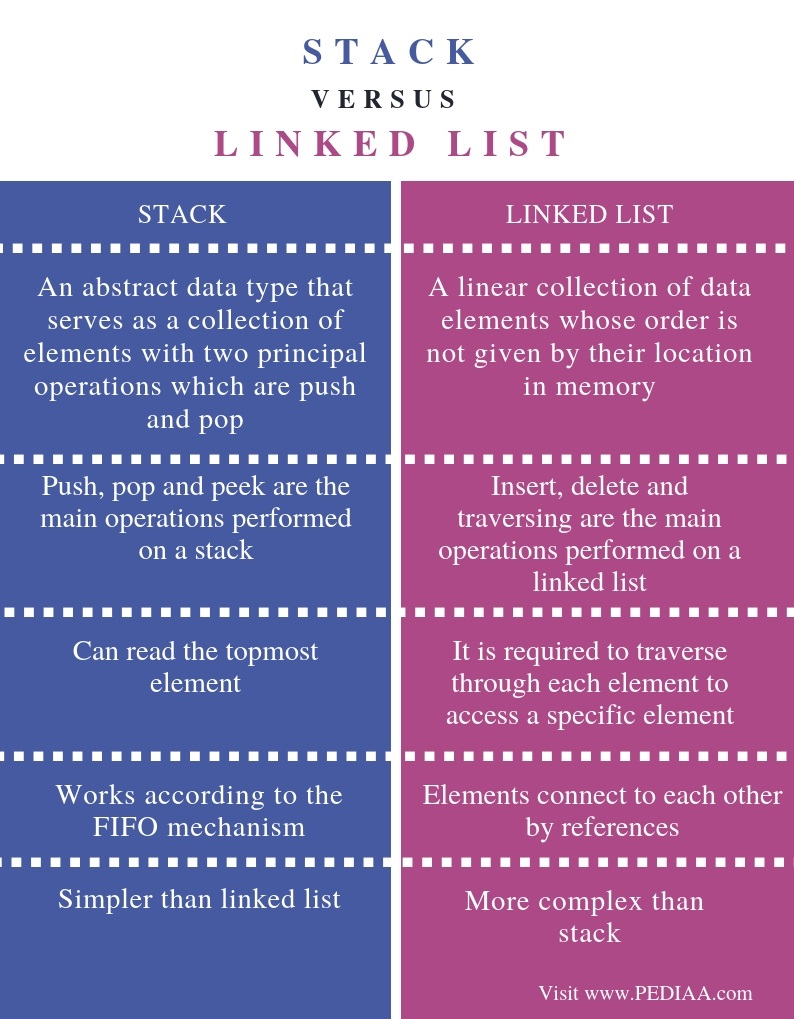
An abstract data type is defined as a mathematical model of the data objects
Abstract Data type (ADT) is a type(or class) of data whose behavior is defined by a set of values and a set of operations.
- It is called “abstract” because
it gives an implementation-independent view.
- The process of providing only the essentials and hiding the details is known as abstraction.
- The definition of ADT only mentions what operations are to be performed but not how these operations will be implemented.
- It does not specify how data will be organized in memory and what algorithms will be used for implementing the operations.
We have three ADTs: List, Queue, Stack
List ADT
- The data is generally stored in a key sequence in a list that has a head structure consisting of count, pointers, and address of compare function needed to compare the data in the list.
- The data node contains the pointer to a data structure and a self-referential pointer which points to the next node in the list.
- A list contains elements of the same type arranged in sequential order and various operations can be performed on the list.
Stack ADT
- In Stack ADT Implementation instead of data being stored in each node, the pointer to data is stored.
- The program allocates memory for the data and the address is passed to the stack ADT.
- The head node and the data nodes are encapsulated in the ADT. The calling function can only see the pointer to the stack.
- The stack head structure also contains a pointer to the top and a count of the number of entries currently in the stack.
- A Stack contains elements of the same type arranged in sequential order.
- All operations take place at a single end that is top of the stack.
Queue ADT
- The queue abstract data type (ADT) follows the basic design of the stack abstract data type.
- Each node contains a void pointer to the data and the link pointer to the next element in the queue. The program’s responsibility is to allocate memory for storing the data.
- A Queue contains elements of the same type arranged in sequential order.
- Operations take place at both ends, insertion is done at the end and deletion is done at the front.
Why we need data structures?
Data
structure provides a means of organizing, managing, and storing &
accessing data efficiently. It also includes the collection of data as
well as the
operations that can be applied to that data.
- Efficiency
- Data Organization
- Re-usability
- invisibility
Applications of Data Structures
The data structures store the data according to the mathematical or logical model it is based on. The type of operations on a certain data structure makes it useful for specific tasks. Here is a brief discussion of different applications of data structures.
Linked List
- Implementing stacks, queues, binary trees and graphs of predefined size.
- Implement dynamic memory management functions of operating system.
- Polynomial implementation for mathematical operations
- Circular linked list is used to implement OS or application functions that require round robin execution of tasks.
- Circular linked list is used in a slide show where a user wants to go back to the first slide after last slide is displayed.
- When a user uses the alt+tab key combination to browse through the opened application to select a desired application
- Doubly linked list is used in the implementation of forward and backward buttons in a browser to move backwards and forward in the opened pages of a website.
- Circular queue is used to maintain the playing sequence of multiple players in a game.
Stacks
- Temporary storage structure for recursive operations
- Auxiliary storage structure for nested operations, function calls, deferred/postponed functions
- Manage function calls
- Evaluation of arithmetic expressions in various programming languages
- Conversion of infix expressions into post-fix expressions
- Checking syntax of expressions in a programming environment
- Matching of parenthesis
- String reversal
- In all the problems solutions based on backtracking.
- Used in depth first search in graph and tree traversal.
- Operating System functions
- UNDO and REDO functions in an editor.
Queues
- It is used in breadth search operation in graphs.
- Job scheduler operations of OS like a print buffer queue, keyboard buffer queue to store the keys pressed by users
- Job scheduling, CPU scheduling, Disk Scheduling
- Priority queues are used in file downloading operations in a browser
- Data transfer between peripheral devices and CPU.
- Interrupts generated by the user applications for CPU
- Calls handled by the customers in BPO
Trees
- Implementing the hierarchical structures in computer systems like directory and file system
- Implementing the navigation structure of a website
- Code generation like Huffman’s code
- Decision making in gaming applications
- Implementation of priority queues for priority based OS scheduling functions
- Parsing of expressions and statements in programming language compilers
- For storing data keys for DBMS for indexing
- Spanning trees for routing decisions in computer and communications networks
- Hash trees
- path-finding algorithm to implement in AI, robotics and video games applications
Graphs
- Representing networks and routes in communication, transportation and travel applications
- Routes in GPS
- Interconnections in social networks and other network based applications
- Mapping applications
- E commerce applications to present user preferences
- Utility networks to identify the problems posed to municipal or local corporations
- Resource utilization and availability in an organization
- Document link map of a website to display connectivity between pages through hyperlinks
- Robotic motion and neural networks
Arrays
- Storing list of data elements belonging to same data type
- Auxiliary storage for other data structures
- Storage of binary tree elements of fixed count
- Storage of matrices
These are a few applications of data structures to make appropriate storage and management of data for specific applications.
Symbol Table is an important data structure created and maintained by the compiler in order to keep track of semantics of variable i.e. it stores information about scope and binding information about names, information about instances of various entities such as variable and function names, classes, objects, etc.