Compiler, Computer software that translates (compiles) source code written in a high-level language (e.g., C++) into a set of machine-language instructions that can be understood by a digital computer’s CPU.
Compilers are very large programs, with error-checking and other abilities.
Some compilers translate high-level language into an intermediate assembly language, which is then translated (assembled) into machine code by an assembly program or assembler. Other compilers generate machine language directly.
The Structure of a Compiler
There are two parts: analysis and synthesis.
Analysis (Front End)
- The analysis part breaks up the source program into constituent pieces and imposes a grammatical structure on them.
- It then uses this structure to create an intermediate representation of the source program.
- If the analysis part detects that the source program is either syntactically ill formed or semantically unsound, then it must provide informative messages, so the user can take corrective action.
- The analysis part also collects information about the source program and stores it in a data structure called a symbol table , which is passed along with the intermediate representation to the synthesis part.
- The synthesis part constructs the desired target program from the intermediate representation and the information in the symbol table.
Different Phases
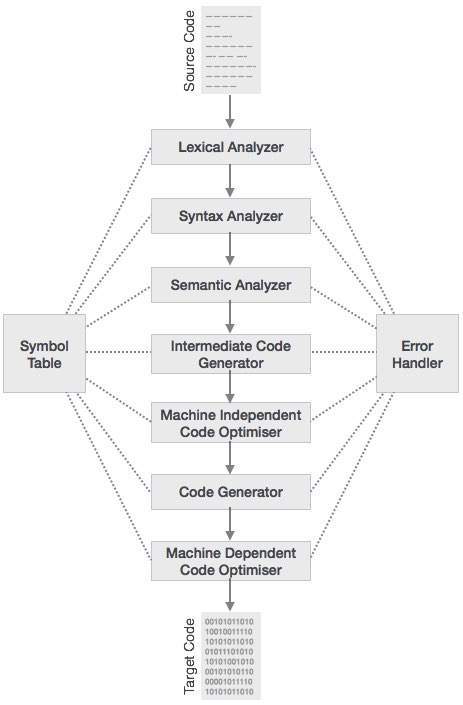
Some compilers have a machine-independent optimization phase between the front end and the back end. The purpose of this optimization phase is to perform transformations on the intermediate representation, so that the back end can produce a better target program than it would have otherwise produced from an unoptimized intermediate representation. Since optimization is optional, one or the other of the two optimization phases will be missing.
1. Lexical Analysis (Scanning)
- The first phase of a compiler is called lexical analysis or scanning .
- The lexical analyzer reads the stream of characters making up the source program and groups the characters into meaningful sequences called lexemes .
- For each lexeme, the lexical analyzer produces as output a token(sequence of characters that represent lexical unit) of the form,
token-name ; attribute-value
that it passes on to the subsequent phase, syntax analysis.
In the token, the first component token-name is an abstract symbol that is used during syntax analysis, and the second component attribute-value points to an entry in the symbol table for this token.
Input: stream of characters
Output: Token
example:
ip: position = initial + rate * 60 (lexemes)
op: <id, 1> <=> <id, 2> <+> <id, 3> <*> <60> (tokens)
2. Syntax Analysis (Parsing)
- The second phase of the compiler is syntax analysis or parsing .
- The parser uses the first components of the tokens produced by the lexical analyzer to create a tree-like intermediate representation that depicts the grammatical structure of the token stream.
- A typical representation is a syntax tree in which each interior node represents an operation and the children of the node represent the arguments of the operation.
Input: Tokens
Output: Abstract Syntax tree
3. Semantic Analysis
- The semantic analyzer uses the syntax tree and the information in the symbol table to check the source program for semantic consistency with the language definition.
- It also gathers type information and saves it in either the syntax tree or the symbol table, for subsequent use during intermediate-code generation.
- Type Checking is taken care of in this phase. This ensures that the
variables are assigned values according to their declaration.
So if a variable have been declared as integer and then assigned a float, the error is trapped by the Semantic Analyzer. - This phase also identifies chunks of code such as operands and operators of statements in the input code.
The output of this phase includes the Parse Tree/ Annotated Parse Tree - The language specification may permit some type conversions called coercion .
4. Intermediate Code Generation
Intermediate code generation produces intermediate representations for the source program. This intermediate representation should have two important properties:
It should be easy to produce
It should be easy to translate into the target machine
Different forms of ICG:
o Post-fix notation
o Three address code
o Syntax tree
Most commonly used form is the three address code (It makes use of at most three addresses and one operator to represent an expression and the value computed at each instruction is stored in temporary variable generated by compiler.).
t1 = inttofloat(60)
t2 = id3 * t1
t3 = id2 + t2
id1 = t3
5. Code Optimization
Code-optimization phase attempts to improve the intermediate code so that better target code will result. Usually better means faster, but other objectives may be desired, such as shorter code, or target code that consumes less power.
In Code Optimization, the code is optimized to remove redundant codes
and the optimize for efficient memory management as well as improve the
speed of execution. The intermediate code ensures that a target code can
be generated for any machine enabling portability across different
platforms.
Output of this phase is the Optimized Code.
6. Code Generation
- The code generator takes an intermediate representation of the source program as input and maps it into the target language.
- Registers or memory locations are selected for each of the variables used by the program.
- Then, the intermediate instructions are translated into sequences of machine instructions that perform the same task.
- A crucial aspect of code generation is the judicious assignment of registers to hold variables.
LDF R2, id3
MULF R2, # 60.0
LDF R1, id2
ADDF R1, R2
STF id1, R1
Symbol Table Management
- The symbol table is a data structure containing a record for each variable name, with fields for the attributes of the name.
- The data structure should be designed to allow the compiler to find the record for each name quickly and to store or retrieve data from that record quickly

