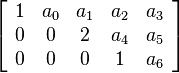Matrix operations mainly involve three algebraic operations which are
addition of matrices, subtraction of matrices, and multiplication of
matrices. Matrix is a rectangular array of numbers or expressions
arranged in rows and columns.
As far as linear algebra is concerned, the two most important operations
with vectors are vector addition [adding two (or more) vectors] and
scalar multiplication (multiplying a vector by a scalar).
Operations
Addition, subtraction and multiplication are the basic operations on
the matrix. To add or subtract matrices, these must be of identical
order and for multiplication, the number of columns in the first matrix
equals the number of rows in the second matrix.
- Addition of Matrices
- Subtraction of Matrices
- Scalar Multiplication of Matrices
- Multiplication of Matrices
Matrix Addition
If A[aij]mxn and B[bij]mxn
are two matrices of the same order then their sum A + B is a matrix, and
each element of that matrix is the sum of the corresponding elements.
i.e. A + B = [aij + bij]mxn
For the Example:
Properties of Matrix Addition: If a, B and C are matrices of same order, then
(a) Commutative Law: A + B = B + A
(b) Associative Law: (A + B) + C = A + (B + C)
(c) Identity of the Matrix: A + O = O + A = A, where O is zero matrix which is additive identity of the matrix,
(d) Additive Inverse: A + (-A) = 0 = (-A) + A, where
(-A) is obtained by changing the sign of every element of A which is
additive inverse of the matrix,
(e) A+B=A+CB+A=C+A}⇒B=C
(f) tr(A±B)=tr(A)±tr(B)
(g) If A + B = 0 = B + A, then B is called additive inverse of A and also A is called the additive inverse of A.
Subtraction of Matrices
If A and B are two matrices of the same order, then we define A−B=A+(−B).
We can subtract the matrices by subtracting each element of one matrix
from the corresponding element of the second matrix. i.e. A – B = [aij – bij]mxn
Scalar Multiplication of Matrices
If A=[aij]m×n
is a matrix and k any number, then the matrix which is obtained by
multiplying the elements of A by k is called the scalar multiplication
of A by k and it is denoted by k A thus if A=[aij]m×n
Then kAm×n=Am×nk=[kai×j]
Properties of Scalar Multiplication: If A, B are matrices of the same order and λ and μ are any two scalars then;
(a) λ(A+B)=λA+λB
(b) (λ+μ)A=λA+μA
(c) λ(μA)=(λμA)=μ(λA)
(d) (−λA)=−(λA)=λ(−A)
(e) tr(kA)=ktr(A)
Multiplication of Matrices
If A and B be any two matrices, then their product AB will be defined
only when the number of columns in A is equal to the number of rows in
B.
The first step in defining matrix multiplication is to recall the definition of the dot product of two vectors. Let r and c be two n‐vectors. Writing r as a 1 x n row matrix and c as an n x 1 column matrix, the dot product of r and c is

Note that in order for the dot product of r and c
to be defined, both must contain the same number of entries. Also, the
order in which these matrices are written in this product is important
here: The row vector comes first, the column vector second.
Properties of matrix multiplication
(a) Matrix multiplication is not commutative in general, i.e. in general A≠BA.
(b) Matrix multiplication is associative, i.e. (AB)C = A(BC).
(c) Matrix multiplication is distributive over matrix addition, i.e. A.(B + C) = A.B + A.C and (A + B)C = AC + BC.
(d) If A is an m × n matrix, then ImA=A=AIn.
(e) The product of two matrices can be a null matrix while
neither of them is null, i.e. if AB = 0, it is not necessary that either
A = 0 or B = 0.
(f) If A is an m × n matrix and O is a null matrix then Am×n.On×p=Om×p. i.e. the product of the matrix with a null matrix is always a null matrix.
(g) If AB = 0 (It does not mean that A = 0 or B = 0, again the product of two non-zero matrices may be a zero matrix).
(h) If AB = AC , B ≠ C (Cancellation Law is not applicable).
(i) tr(AB)=tr(BA).
j) There exist a multiplicative identity for every square matrix such AI = IA = A
Matrix Transpose
If A is m × n, the transpose of A is the n × m matrix, denoted by A^T , whose columns are formed from the corresponding rows of A.
A square matrix has the same number of rows and
columns. An identity matrix is a square matrix with ones
on the diagonal from upper left to lower right and zeros
elsewhere. For example:
I =
1 0 0
0 1 0
0 0 1
Such a matrix is often denoted I.
REF
https://www.cliffsnotes.com/study-guides/algebra/linear-algebra/matrix-algebra/operations-with-matrices
https://byjus.com/jee/matrix-operations/