Discuss the concept of hubs and authorities in multimedia indexing.
https://nlp.stanford.edu/IR-book/html/htmledition/hubs-and-authorities-1.html
https://safecont.com/en/ranking-urls-hubs-authorities/
- given a query, every web page is assigned two scores. One is called its hub score and the other its authority score .
- For any query, we compute two ranked lists of results rather than one.
- The ranking of one list is induced by the hub scores and that of the other by the authority scores.
- There are two primary kinds of web pages useful as results for broad-topic searche
- There are authoritative sources of information on the topic. We will call such pages authorities. They are the pages that will emerge with high authority scores.
- There are pages on the Web that are hand-compiled lists of links to authoritative web pages on a specific topic. These hub pages are not in themselves authoritative sources of topic-specific information.
- They are compilations made by someone with an interest in the topic. These hub pages are the pages that will emerge with high hub scores.
- A good hub page is one that points to many good authorities;
- A good authority page is one that is pointed to by many good hub pages.
Explain how correlated terms are built form local document set through association clustering.
Discuss page rank algorithm in the context of a small web consisting of three pages A,B and C whereby page A links to the pages B and c, page B links to page c and page c links to page A. Assume the damping factor is 0.5. Find the page rankings also.
PR(A) = 0.5 + 0.5 PR(C)
PR(B) = 0.5 + 0.5 (PR(A) / 2)
PR(C) = 0.5 + 0.5 (PR(A) / 2 + PR(B))
We get the following PageRank™ values for the single pages:
PR(A) = 14/13 = 1.07692308
PR(B) = 10/13 = 0.76923077
PR(C) = 15/13 = 1.15384615
The sum of all pages' PageRanks is 3 and thus equals the total number of web pages.
What are the different methods of query expansion?
https://en.wikipedia.org/wiki/Query_expansion
Explain how the URL frontier maintains the politeness and priority property of crawlers.
https://nlp.stanford.edu/IR-book/html/htmledition/the-url-frontier-1.html
Consider a Web graph with three nodes 1,2, and 3. The links are as follows: 'l->2,3->2,2->1, 2->3. Write down the transition probability matrices for the surfer's walk with teleporting, with the value of teleport probability alpha q=0.5. Derive the ranking of the nodes using Page Rank algorithm.


What is pseudo relevance feedback? What is its disadvantage?
Suppose that a user's initial query is 'cheap CDs cheap DVDs extremely cheap CDs'. The user examines two documents, dl and d2. He judges dl, with the content 'CDs cheap software cheap CDs' relevant and d2 with content 'cheap thrills DVDs'non-relevant. Assume that we are using direct term frequency (with no scaling and no docuhrent frequency). There is no need to length-nonnalize vectors. Using Rocchio
relevance feedback what would the revised query vector be after relevancef eedback?
Assume α = l, β = 0.75, γ= 0.25.


Discuss Page Ranking.
page rank is a measure of how 'important' a web page is.
It works on the basis that when another website links to your web page,
it's like a recommendation or vote for that web page. Each link
increases the web page's page rank. ... It's a vote from a less-known
website that isn't relevant to the subject.
Write note on the User Relevance Feedback strategy for query reformulation. Explain the process of Query Expansion and Term Reweighting for vector model.
Write note on the process of query expansion through Local Clustering. Explain three cluster building strategies for local clustering in detail (association clusters, metric clusters, and scalar clusters).
Module4
Discuss how XML retrieval is performed
Explain how R tree helps in mapping objects into f-D space to do clustering
Explain the application of GEMINI method in colour images. Discuss. its.application in medical field.
Explain any one data structure used in multimedia indexing
Explain the generic multimedia indexing approach for multimedia IR
Briefly explain the vector space model for information retrieval from XML documents
What are spatial access methods?
Explain the generic multimedia indexing approach for multimedia IR
.
Briefly explain the vector space model for information retrieval from XML documents
Aim: to have each dimension of the vector space encode a word together with its position within the XML tree.
How: Map XML documents to lexicalized subtrees.
Take each text node (leaf) and break it into multiple nodes, one for each word. E.g. split Bill Gates into Bill and Gates
Define the dimensions of the vector space to be lexicalized subtrees of documents – subtrees that contain at least one vocabulary term.
We can now represent queries and documents as vectors in this space of lexicalized subtrees and compute matches between them, e.g. using the vector space formalism.

Write note on two type of multimedia similarity queries Whole Match and Sub-pattern Match queries with example.
Why we need spatial access methods instead of sequential scanning to access multimedia objects? Explain GEMINI algorithm (Explain each step).
We need spatial access methods to organizing spatial data (multidimensional data such as points, line
segments, regions, polygons, volumes, or other kinds of geometric
entities) that allows the efficient retrieval of data according to a set of search criteria.
What do you mean by curse of dimmsionality? Discuss the difference between feature selection and feature extraction with example. How do these two process contribute to dimensionalitv reduction?
The curse of dimensionality basically
means that the error increases with the increase in the number of
features. he dimension of a dataset corresponds to the number of
attributes/features that exist in a dataset. A dataset with a large
number of attributes, generally of the order of a hundred or more, is
referred to as high dimensional data. It refers to the fact that algorithms are harder to design in
high dimensions and often have a running time exponential in the
dimensions. A higher number of dimensions theoretically allow more information to be stored, but practically it rarely helps due to the higher possibility of noise and redundancy in the real-world data.
Some of the difficulties that come with high dimensional data manifest
during analyzing or visualizing the data to identify patterns, and some
manifest while training machine learning models. The difficulties
related to training machine learning models due to high dimensional data
is referred to as ‘Curse of Dimensionality’. The popular aspects of the
curse of dimensionality; ‘data sparsity’ and ‘distance concentration’
Feature selection is the process of choosing precise features, from a features pool. This helps in simplification, regularization and shortening training time. This can be done with various techniques: e.g. Linear Regression, Decision Trees.
Feature extraction is the process of converting the raw data into some other data type, with which the algorithm works is called Feature Extraction. Feature extraction creates a new, smaller set of features that captures most of the useful information in the data.
The main difference between them is Feature selection keeps a subset of the original features while feature extraction creates new ones.
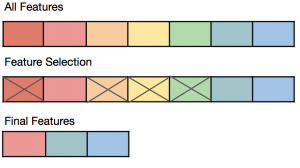

What is Feature selection
- Problem of selecting some subset of a learning algorithm’s input variables upon which it should
focus attention, while ignoring the rest. In other words, Dimensionality Reduction - Especially when dealing with a large number of variables there is a need for Dimensionality
Reduction. - Feature Selection can significantly improve a learning algorithm’s performance
- Many domains have tens of thousands of variables out of which most are irrelevant and redundant.
Feature selection limits the training data and reduces the amount of computational resources used.
It can significantly improve a learning algorithms performance.
Feature Extraction
- Feature extraction is an attribute reduction process. Unlike feature selection, which ranks the
existing attributes according to their predictive significance, feature extraction actually transforms
the attributes. The transformed attributes, or features, are linear combinations of the original
attributes. - The general workflow involves applying feature extraction on given data to extract features and
then apply feature selection with respect to the target variable to select a subset of data. In effect,
this helps improve the accuracy of a model. - For example, in an unsupervised learning problem, the extraction of
bigrams from a text, or the extraction of contours from an image are examples of feature
extraction. - Feature extraction can be used to extract the themes of a document collection, where documents
are represented by a set of key words and their frequencies